文献整理 · 开山篇
Last updated on May 12, 2024 pm
TarDAL
Title
Target-aware Dual Adversarial Learning and a Multi-scenario Multi-modality Benchmark to Fuse Infrared and Visible for Object Detection [CVPR] 2022
Motivation
Previous approaches:
1.Aiming at generating an image of high visual quality
2.Discover commons underlying the two modalities and fuse
upon the common space either by iterative optimization or deep networks
3.Neglect that modality differences implying the complementary infomation
which extremely important for both fusion and subsequent detection taskIntro
Visible image, provides rich details with high spatial resolution
(under welldefined lighting conditions)Infrared image, capturing ambient temperature variations emitted from objects,
highlight structures of thermal targets (insensive to lighting changes)Their evident appearance discrepancy, it's challenging to fuse visually appealing images and/or to support higher-level vision tasks (by making full use of the complementary info from the infrared and visible images)
The fusion emphasizes more on "seeking commons" but neglect the differences of these two modalities on presenting structure info of targets and textural details of ambient background.
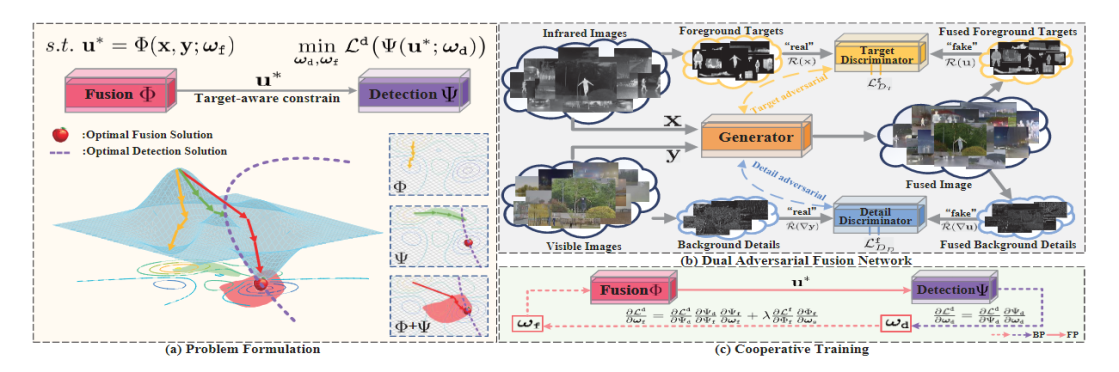
Method
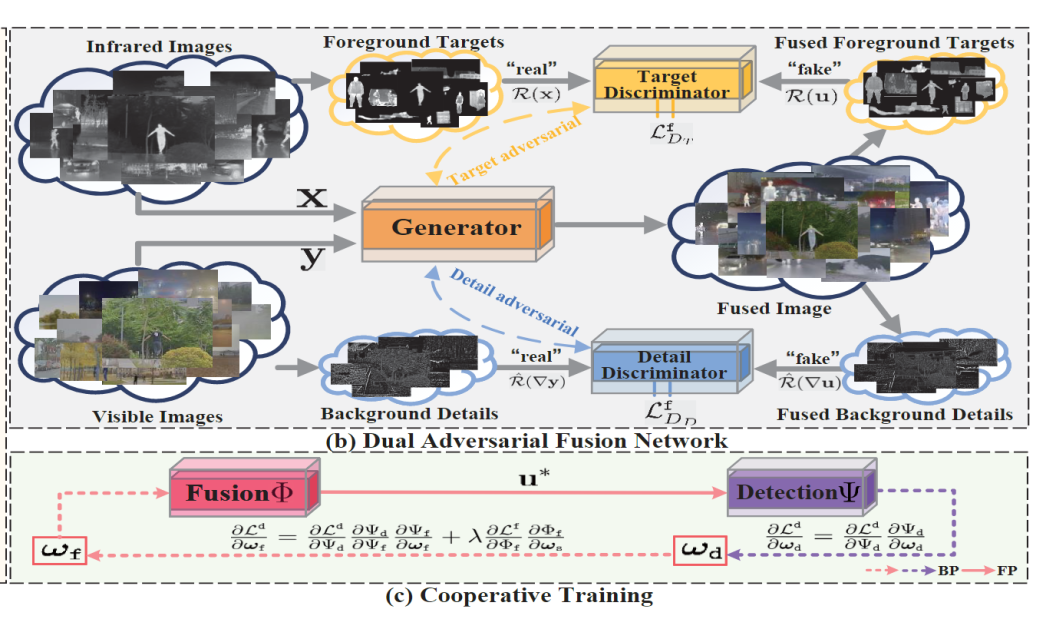
Fusion network:
Composed of one generator and two target-aware discriminators,
and a commonly used detection network [Detection-oriented fusion]
Discriminator:
Distinguishes foreground(structure infomation of targets),
i.e., thermal targets(infrared image), and differentiates
the background, i.e., textural details(visible image)
Derive a cooperative training schemeStructure diagram

Loss function
Detection network backbone: YOLOv5
Generator: 1.Structural similarity index (SSIM)
Contributes to generate a fused image that preserves overall structures and maintains a similar intensity distribution as source images.
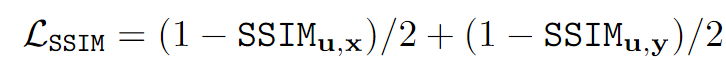
2.Pixel loss (based on the saliency degree weight (SDW))
To balance the pixel intensity distribution of source images
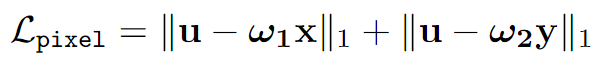 w1, w2 are
calculated by saliency value of x and y.
w1, w2 are
calculated by saliency value of x and y.
Target and detail discriminators: Wasserstein divergence (with target mask m)
The target discriminator \(D_T\) is used to distinguish the foreground thermal targets of fused result to the infrared while the detail discriminator \(D_D\) contributes to distinguish the background details of fused result to the visible.
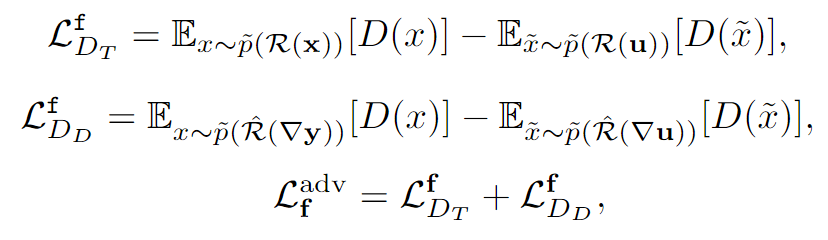
SeAFusion
Title
Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network [Image Fusion] 2022
Intro
The infrared sensor captures thermal radiation emitted from objects, which could highlight salient targets, but the infrared image neglects texture and is vulnerable to noise.
The visible sensor captures reflective light infomation, the visible image usually contains abundant texture and structure info, but is sensitive to the environment, such as illumination and occlusion.
Complementary info: to fuse Ir and Vis image, to generate a desired image.
Fused image has been broadly used as a preprocessing module for high-level vision tasks, e.g., object detection, tracking, semantic segmentation.
Motivation
Pressing challenges:
1.The existing fusion algorithms are inclined to pursue better visual quality
and higher evaluation metrics but seldom systematically consider
whether fused image can facilitate high-level vision tasks
Some studies: cannot effectively enhance/boost the semantic info in the fused image
2.Neither visual comparison nor quantitative evaluation (evaluation manners)
reflects the facilitation of fused images for high-level vision tasks
3.Not effective in extracting fine-grained detail features
4.Ignore the demand for real-time image fusionOurs network:
SeAFusion, can be used for achieving real-time Ir & Vis image fusion
Method
1.Simultaneously obtaining superior performance in
both image fusion and high-level vision tasks.
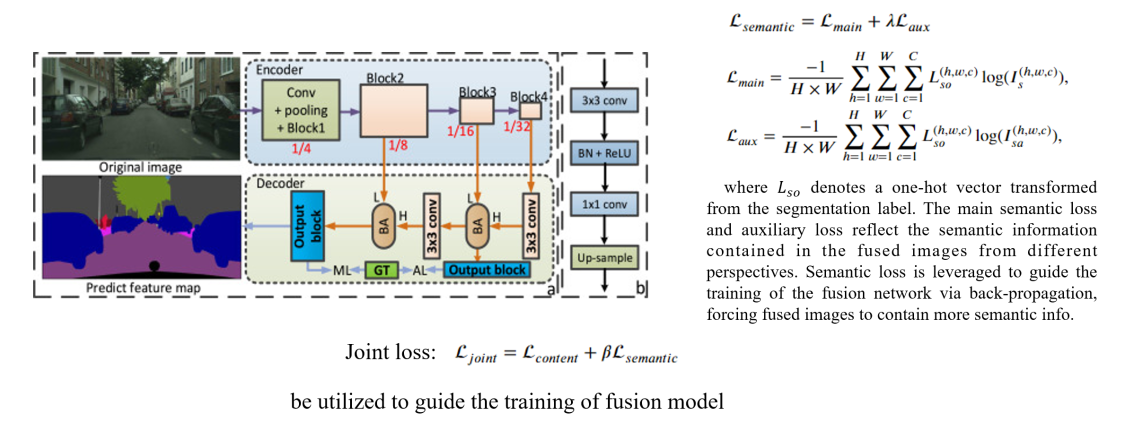
2.A segmentation network to predict the segmentation results
on fused images, which is utilized to construct semantic loss
(is leveraged to guide the training of the fusion network via back-propagation,
so the loss can flow back to the image fusion module
to forcing fused images to contain more semantic infomation).
3.Real-time: light-weight network based on GRDB (gradient residual dense block)
to boost the description ability for fine-grained details and achieve feature reuse.
4.The authors proposed a joint low-level and high-level adaptive training strategy
to achieve simultaneously impressive performance in both
image fusion and various high-level vision tasks.Structure diagram
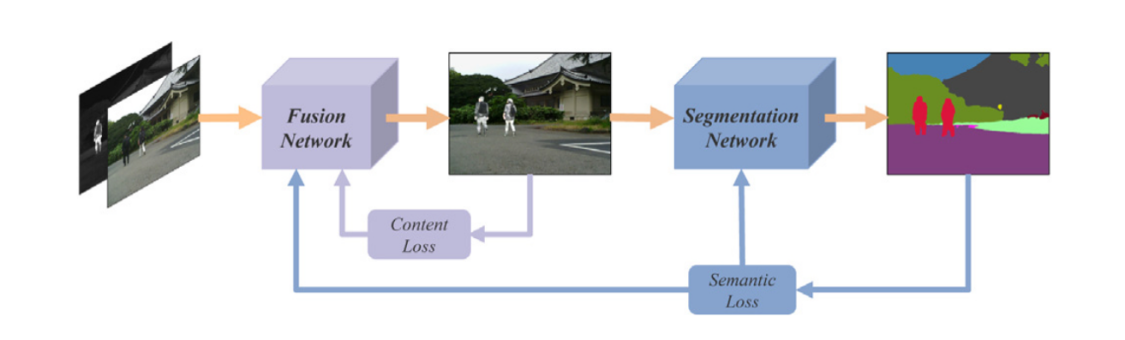
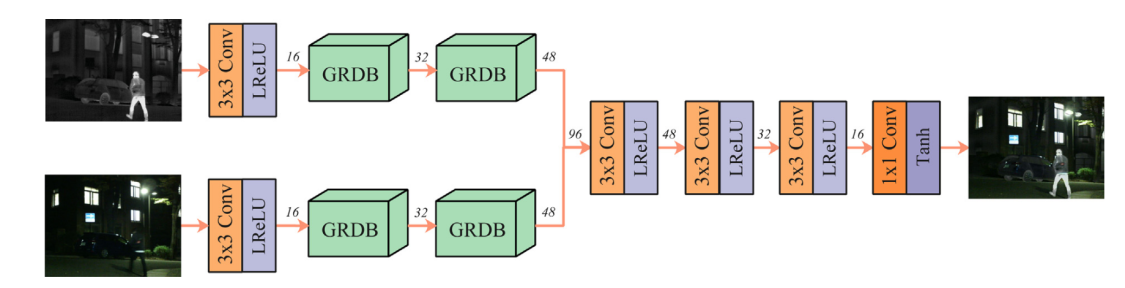
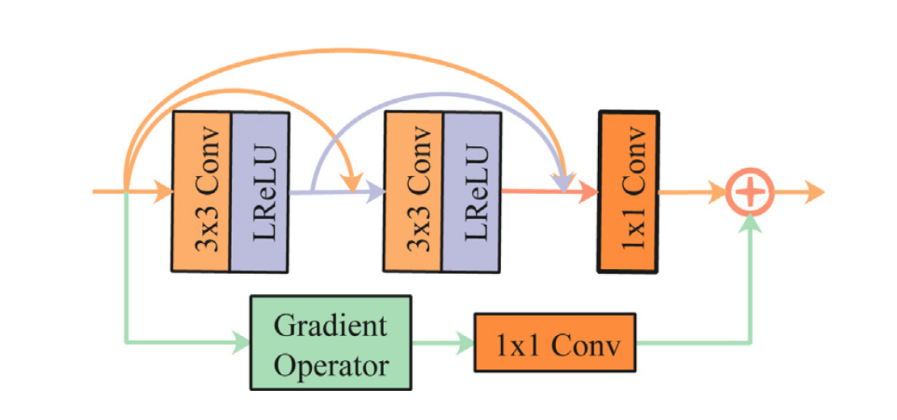
分析
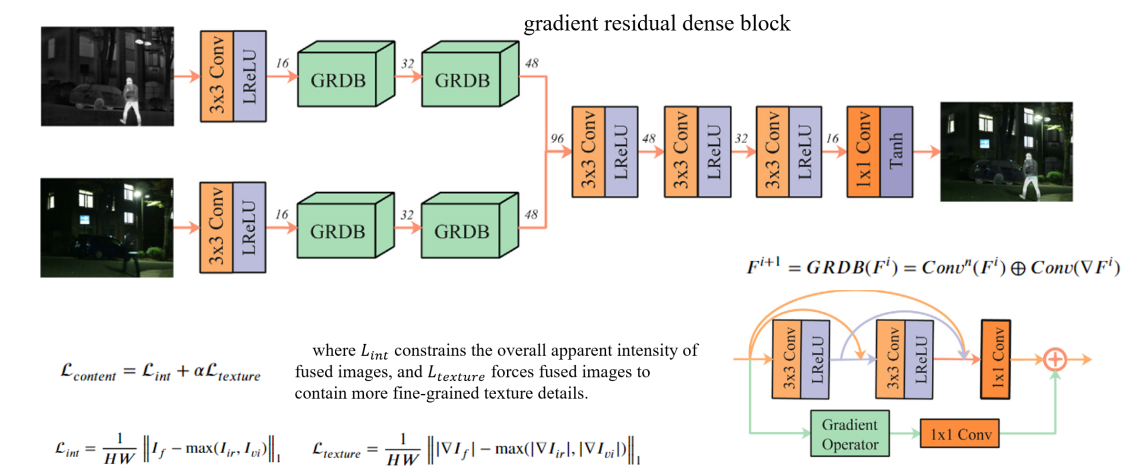

注:分割网络的backbone采用YOLOv5网络
SegMiF
Title
Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation [ICCV] 2023
Abstract
Early efforts boost performance for only one task.
This paper, SegMiF can dual-task correlation to promote the performance of both tasks (fusion and segmentation).
Intro
Contributions:
1.SegMiF contains two modules, i.e., fusion network
and common segmentation network.
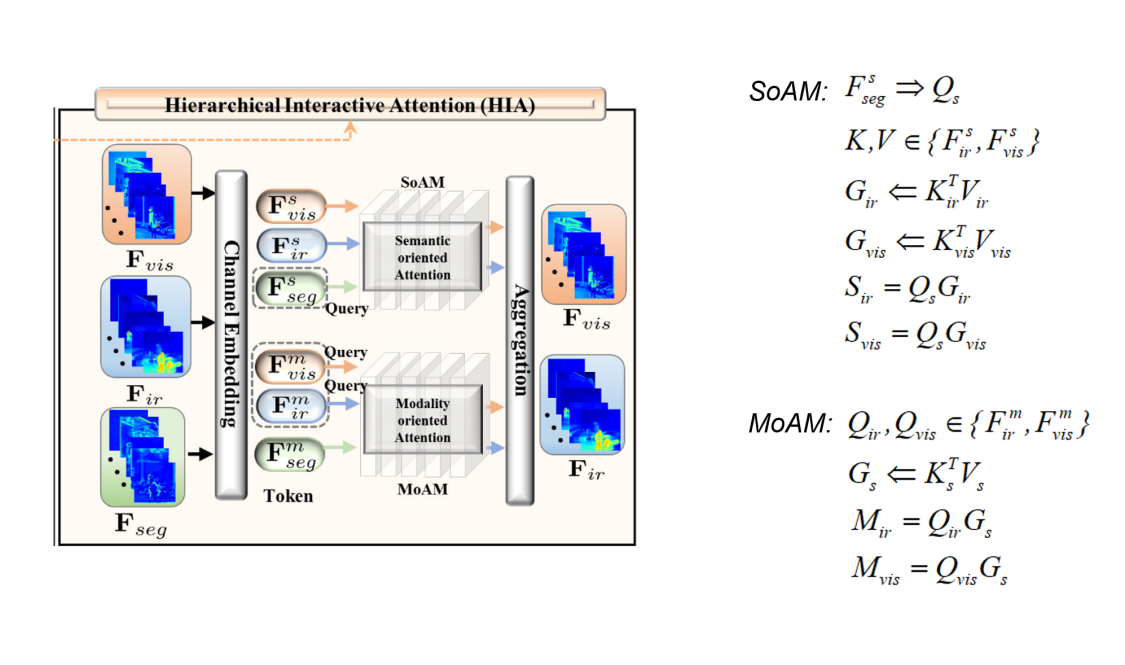
2.Hierarchical interactive attention (HIA) block.
Fine-grained mapping of all the vital infomation between fusion and segmentation.
Modality-/Semantic- oriented features can be fully mutual-interactive
(bridge the feature gap between fusion and segmentation).
3.Dynamic weight factor, automatically adjust the corresponding weights
of each task (optimal parameters).
4.Interactive feature training scheme.
5.Construct an imaging system (benchmark).Structure diagram
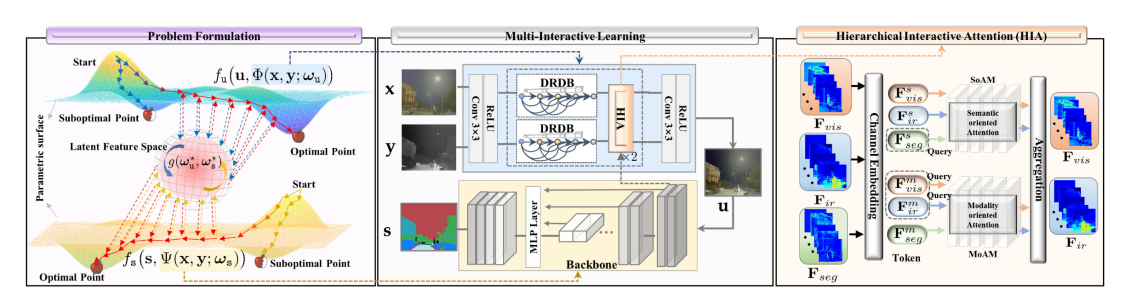
分析
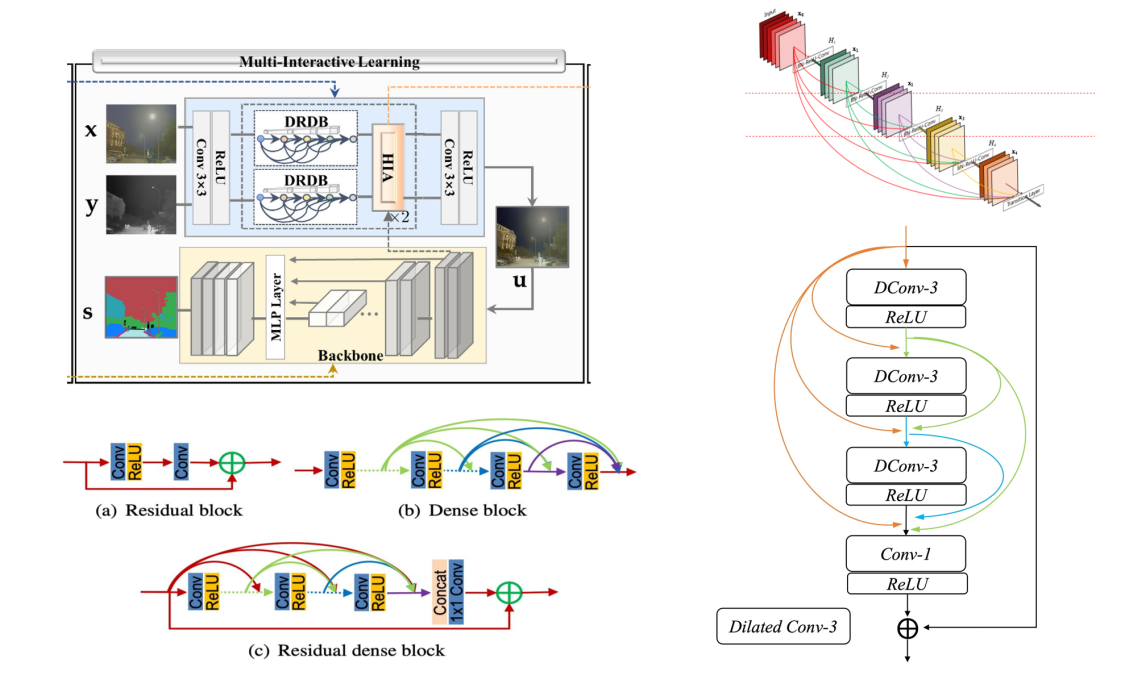
 注:分割网络是论文[SegFormer: Simple and Efficient Design for Semantic
Segmentation with Transformers]的内容
注:分割网络是论文[SegFormer: Simple and Efficient Design for Semantic
Segmentation with Transformers]的内容
分割网络: 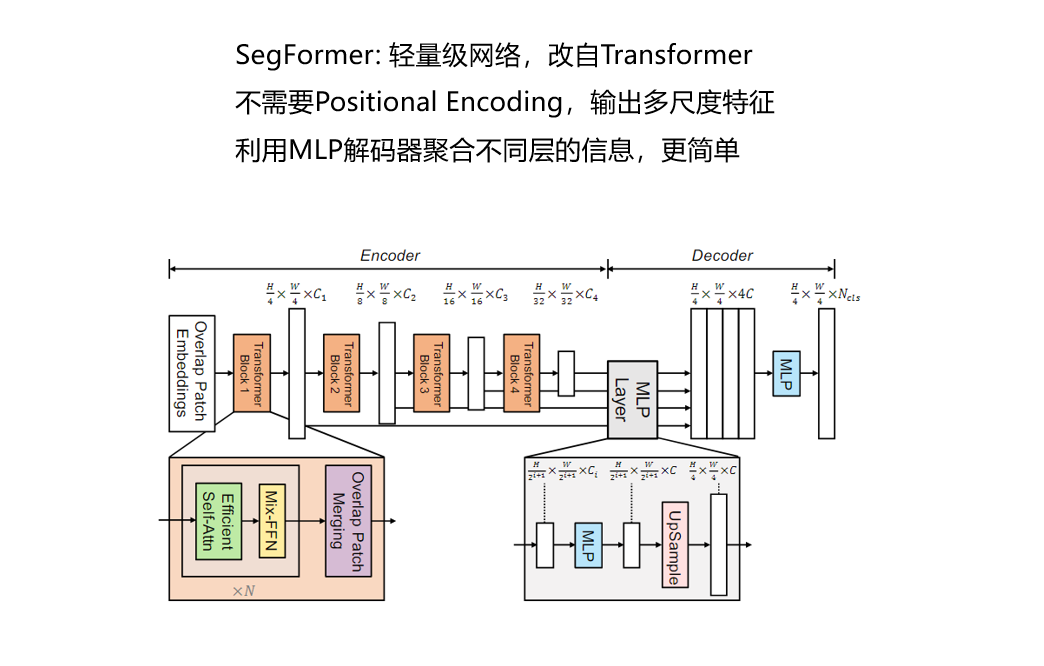
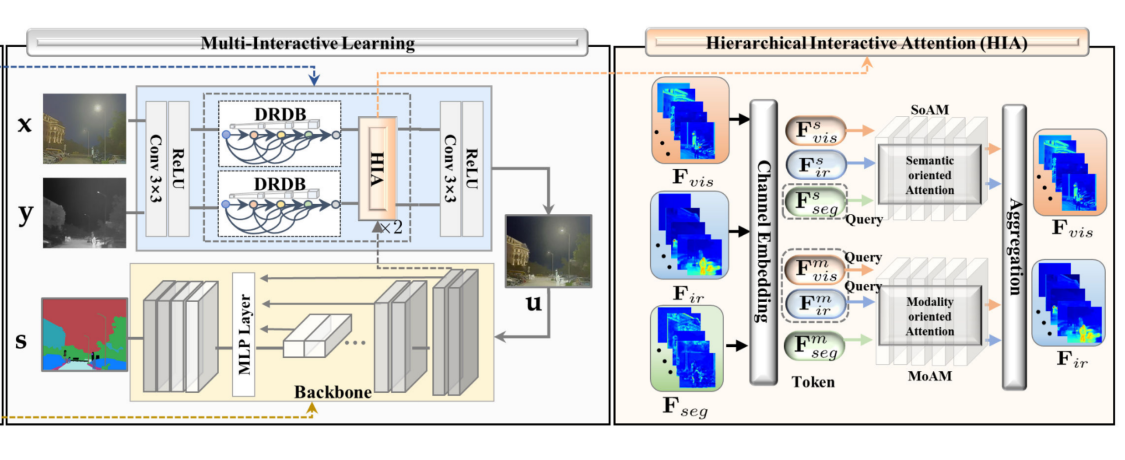
HIA
1.SoAM (Semantic-oriented attention module)
SoAM utilizes the token \(F_{seg}^{s}\) to generate the query \(Q_s\), which represents the inhere semantic information that needs to be enhanced.
The global context representation of each can be calculated by as \(K_{ir}^{T}\cdot V_{ir} (G_{ir})\) and \(K_{vis}^{T}\cdot V_{vis} (G_{vis})\) , 其中K, V ∈ {\(F_{ir}^{s}\), \(F_{vis}^{s}\)}
\(S_{ir} = Q_s\cdot G_{ir}\), \(S_{vis} = Q_s\cdot G_{vis}\)
SoAM to provide more semantic attention for the modality feature.
2.MoAM (Modality-oriented attention module)
MoAM introduce two modality queries \(Q_{ir}\) and \(Q_{vis}\) ∈ {\(F_{ir}^{m}\), \(F_{vis}^{m}\)}
The global context of segmentation \(G_s\) by \(K_{s}^{T}\cdot V_s\)
\(M_{ir} = Q_{ir}\cdot G_s\), \(M_{vis} = Q_{vis}\cdot G_s\)
MoAM to investigate the significant feature from semantic contexts.
目标函数
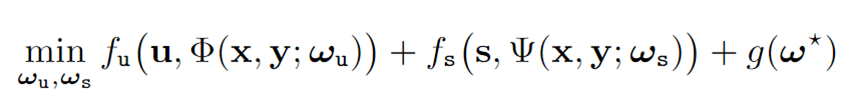
损失函数: 
损失函数中涉及了两个常用的概念:
结构相似度、显著性图
1.结构相似度SSIM主要用来衡量两幅图亮度、对比度和结构的相似性
详见"专业笔记"中所述
2.显著性图主要用来计算MSE损失中的显著性参数m
源自论文: Infrared and visible image fusion based on visual saliency map
and weighted least square optimization相关内容
当CNN层数变深时,输出到输入的路径就会变得很长。
梯度反向传播,到达输入层可能就会消失。
DenseNet是一种深度卷积神经网络,引入密集连接(Dense Connection)将前面所有层与后面的层建立密集连接。
与ResNet的关键区别是,ResNet是简单相加,DenseNet是进行连接。
DenseNet通过基本构建单元Dense Block实现稠密连接对特征进行重用,实现信息共享,并能增强梯度流动,避免梯度消失。
过渡层(Transition Layer)控制通道数(稠密块会带来通道数的增加),防止模型过于复杂。
DenseNet在模型精度和泛化能力上通常表现优异,训练更稳定,但结构仍比较复杂,需要消耗较多的计算资源和时间,内存占用大。
ResNet(Residual Neural Network)是基于残差学习框架的神经网络,其在前向网络中增加了一些快捷连接
Shortcut(Short) Connection/Skip Connection,这些连接会跳过某些层,将数据直接传到之后的层。
ResNet对网络深度增加带来的梯度消失或爆炸、网络退化(由于训练和测试误差的积累导致正确率趋于饱和甚至下降,
与过拟合(训练误差小,测试误差大,泛化能力差)不同)等问题具有一定的作用,增加了非线性,
一定程度上抑制了语义间隙的影响,但模型表现可能略逊一筹。
残差块(Residual Block)是ResNet的基本组成成分。空洞卷积(Dilated/Atrous Convolution)可以增加卷积核的尺寸,如原本3*3的卷积核可以扩充至5*5,
但有效的参数个数不变,仍为9个,剩余的位置不予考虑(空洞/零),利用超参数“扩张率”来定义卷积核处理数据时各值的间距
(可以理解为空洞数),在扩大了感受野的同时,避免了Pooling操作,从而保持分辨率不变。
PS:正常扩大感受野会带来计算量的增加,后面进行池化的降采样处理可以降低计算量,但是空间分辨率也随之降低了。
感受野(Receptive Field)越大,捕获的图像区域越大,对图像全局的特征提取能力也就越强。
而且对于目标检测任务而言,最后一层特征图(Feature Map)的感受野大小要大于等于输入图像大小,否则分类性能会不理想。
一般而言,感受野越大、网络越深,对复杂问题求解的模型性能越好。