文献整理 · 脉络篇(一)
Last updated on September 29, 2024 pm
声明:本文是根据Visual Information Processing Laboratory (VIP Lab)的一位博学多才的博士师兄的知乎专栏内容进行归纳总结的,地址:部分基于深度学习的红外与可见光图像融合模型总结
引言
传统方法用于图像融合的一些问题:
- 没有完全考虑不同模态图像的特性,使用同种方法对不同模态图像进行特征提取可能不会提取到最有效的信息;
- 融合规则是人工设计的简单规则,例如最大值法、平均值法,对于融合结果有限制。
深度学习方法做融合的优势:
- 不同的网络分支可以对不同模态的图像进行特征提取,甚至对同种模态使用不同分支提取多种信息;
- 融合策略可以通过学习得到,可不经过人工设计的融合规则获取融合结果。
近两年做红外-可见光图像融合的深度学习模型也是以下面的模态特点为基础的:
红外图像独有的信息为像素值幅度信息,能够体现温度显著性,温度越高的目标像素值越大;可见光图像独有的信息为纹理细节信息,多数红外图像中模糊的区域在可见光图像中则具有良好的细节,所以一些自监督模型在设计损失函数时针对红外图像的损失项使用的是MSE/L2-norm,保持温度显著性信息,而针对可见光图像使用的是SSIM或者梯度算子,保持细节纹理信息。自监督方法需要设计出合理的指标作为损失函数。
根据时间来分类,2019年之前基本都是有监督模型或者直接套用预训练模型,2020年开始有自监督和GAN模型出现,整体还是修改网络结构和损失函数,个别模型思考了不同模态信息的保留方式,亦有加入了self-attention机制的融合模型。到了2021年,涌现了很多的深度学习模型,也相应诞生了很多新的处理思路。很多学者开始思考到底在红外与可见光图像融合中该如何定义互补信息、如何计算每种模态下图像具有的互补信息,以及如何有效地融合这些信息?展现在模型上,就有了基于显著性的模型、基于transformer的模型等,不再是简单地修改损失函数和网络结构,不再简单地将红外图像的特有信息定义为像素幅度、可见光图像的特有信息定义为纹理细节。同时,还出现了多任务融合模型,例如将超分和融合一起做的端对端模型CF-Net。任务驱动的融合方法也是一种趋势,如SeAFusion。
总体来说,红外与可见光图像融合包含有监督模型、无监督/自监督模型、GAN、显著性模型、transformer/self-attention、多任务驱动、不同分辨率下的融合模型、引导滤波辅助的模型等。下面根据年份对其中一部分模型做简单的介绍。
1.DenseFuse
A Fusion Approach to Infrared and Visible Images (Transactions on Image Processing, 2018)
DenseFuse一般认为是第一个使用深度学习模型对红外与可见光图像进行融合的方法,也是一种有监督学习模型。该模型将红外与可见光图像分解为base part和detail part两部分,其中base part直接用平均法进行融合,detail part通过一个预训练的VGG网络先进行特征提取,然后使用multi-layers fusion strategy基于已有特征图得到融合权重图,将权重图和特征图相乘,再和另一模态的结果相加视为融合特征图的结果。
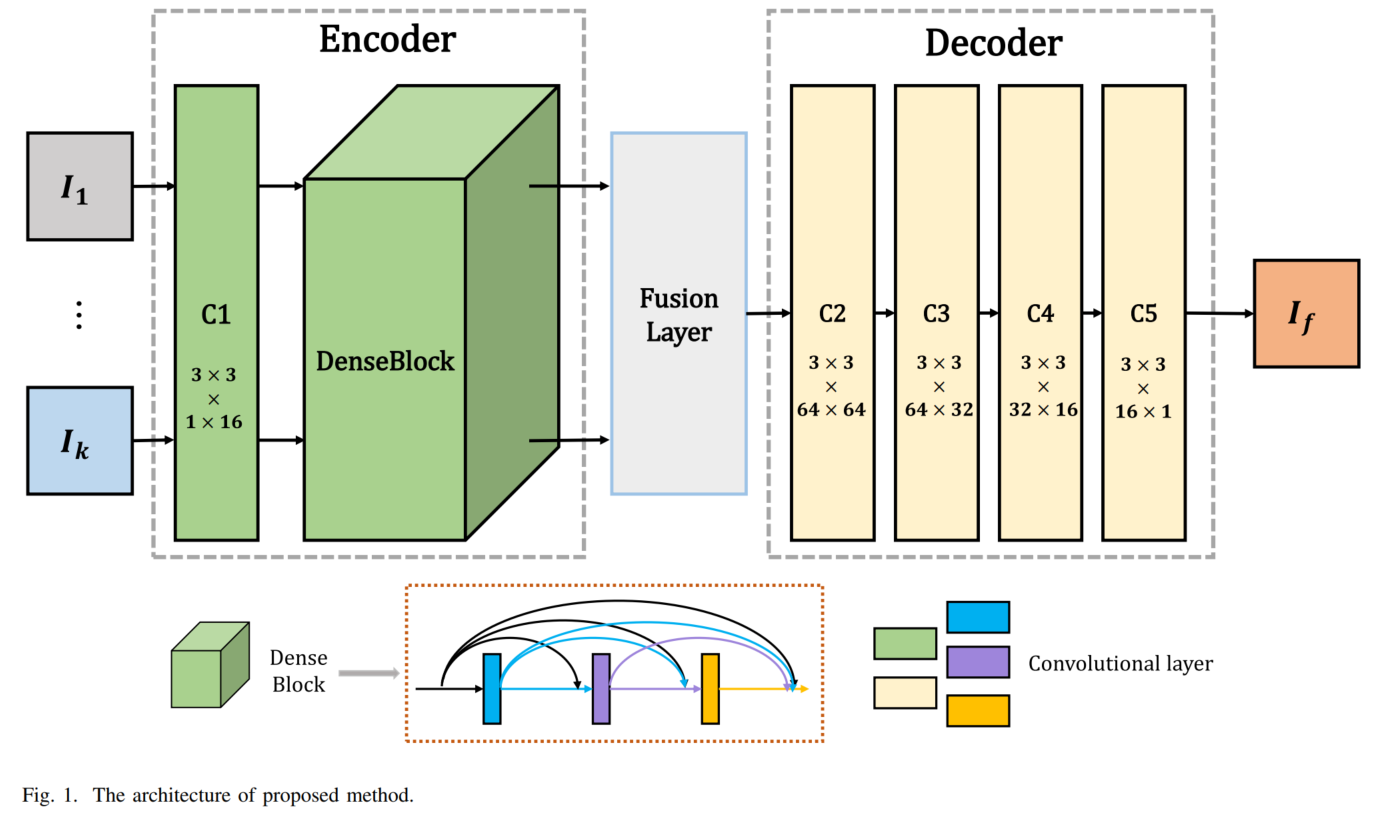
实现:经过L1-norm和average获得activity level map,然后继续基于该activity level map,使用softmax计算final activity level map,该结果和两个模态的detail part分别相乘后再相加就是detail part的融合结果,这一思想与Infrared and Visible Image Fusion using a Deep Learning Framework(International Conference on Pattern Recognition, 2018)中的融合策略一致。Base part和detail part都完成融合后,将这两个结果相加得到最终的融合结果。
图像分解与重建使用的是预训练过的自编码器,而此前的论文中对图像分解还多用的是传统的变换域分解方法。可以说DenseFuse不再使用传统图像融合的图像分解方法,取而代之的是利用了卷积层最擅长的特征提取能力,一个优势是提取到的特征对不同场景图像的适应性要好。
模型的训练是以可见光图像作为输入和输出训练得到一个自编码器,编码器中加入了dense connection,有利于层之间信息的传播。使用的损失函数为MSE和SSIM。训练完成后直接在编码器和解码器之间加入以上提及的特征图融合方法即可。
DenseFuse整体思路和2020年很多模型的思路差不多,其实都是用卷积神经网络作为特征提取与重建模块,不过由于DenseFuse在训练自编码器时使用的只有可见光图像,对红外图像的特征提取能力有一定限制,因此针对融合所需要的互补信息的提取能力可能也存在一定的限制。不过相对于传统方法提升较好,尤其是不同场景下融合结果中的伪影较少。
2.FusionGAN
A generative adversarial network for infrared and visible image fusion (Information Fusion, 2019)
这是首个使用GAN来融合红外与可见光图像的模型,通过生成器和判别器之间的对抗学习避免人工设计activity level和融合规则。其中生成器同时将红外图像与可见光图像作为输入,输出融合图像;判别器将融合图像与可见光图像作为输入,得到一个分类结果,用于区分融合图像与可见光图像。在生成器和判别器的对抗学习过程中,融合图像中保留的可见光信息将逐渐增多。训练完成后,只保留生成器进行图像融合即可。由于可见光图像的纹理细节不能全部都用梯度表示,所以需要用判别器单独调整融合图像中的可见光信息。
实际训练中的生成器和判别器的平衡不好把握,FusionGAN的融合结果对比度不是很好,红外目标的显著性保留的不是很好。
3.NestFuse
An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models (IEEE Transactions on Instrumentation and Measurement, 2020)
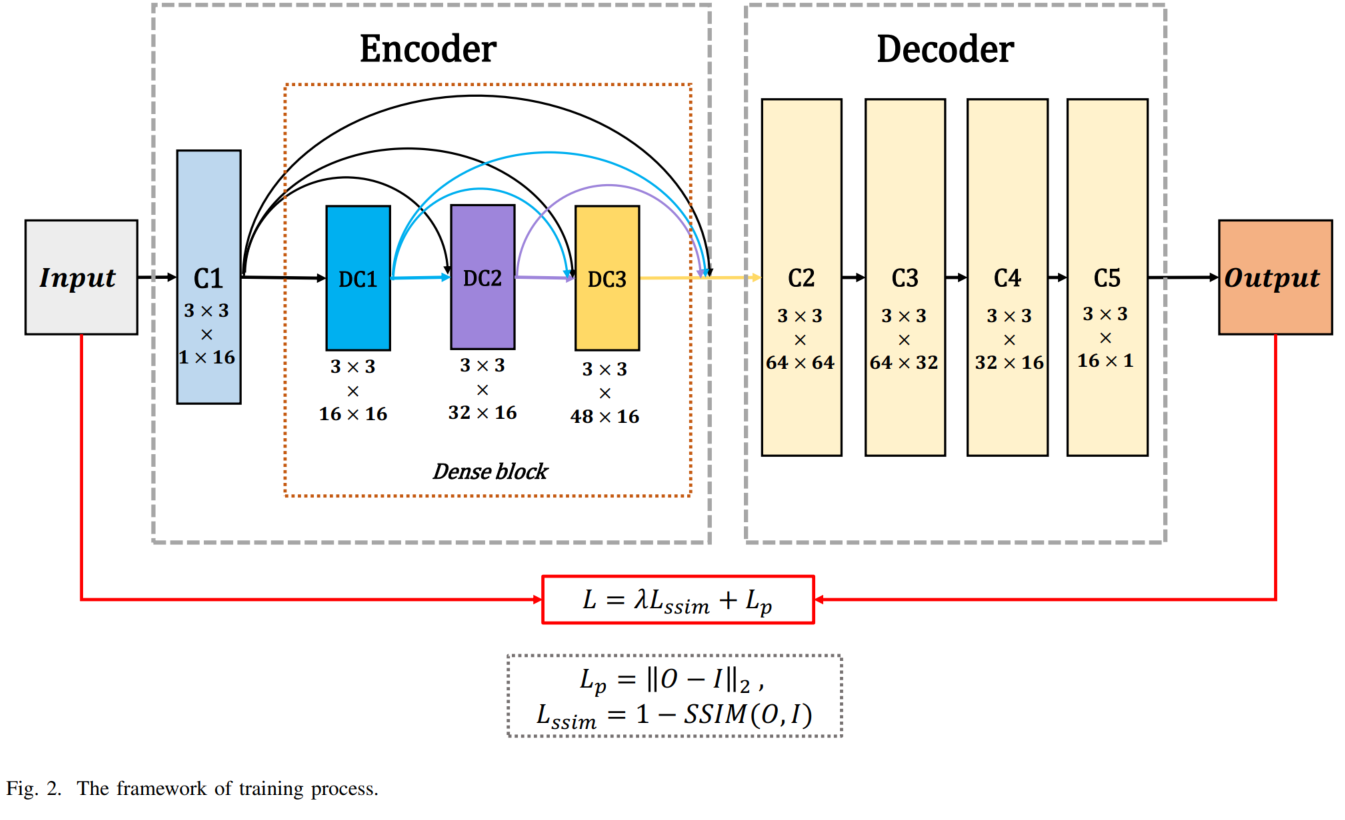
NestFuse可以说是DenseFuse的升级版本,仍然是有监督模型,在第一阶段训练自编码器时用多张可见光图像作为输入输出来训练网络。编码器的结构与DenseFuse没有太大差异,不同之处就是多个卷积层输出的特征图都会进行融合,因此NestFuse是一种多尺度融合模型,对下采样带来的细节损失有一定保护效果。融合模块使用spital attention和channel attention生成显著图来进行融合,解码器加入了nest connection,保护编码器提取到的多尺度特征。
训练完成后的融合模块则不需要训练,仍然是传统方法,采用了两个通道的attention:Spital attention和channel attention分别在同一图像内对不同像素生成显著性和不同特征图之间的通道维度生成显著性。经过spital attention和channel attention后可以得到两个特征图,直接进行平均法得到融合特征图。
NestFuse虽然在解码器阶段使用了nest connection,不过和之前的有监督模型一样,针对模态之间的互补信息提取的较少,并且融合规则仍然是人工设计的方法,不能针对红外与可见光特有的信息进行融合。
4.DIDFuse
Deep Image Decomposition for Infrared and Visible Image Fusion (International Joint Conferences on Artificial Intelligence, 2020)
最早使用深度学习方法的模型,基本都是先用传统方法将输入图像分解为base part和detail part,相当于图像中的低频部分和高频部分。DIDFuse则是将深度图像分解方法引入红外与可见光图像融合模型中,在训练阶段通过编码器将图像分解为背景部分和细节部分,测试阶段将红外与可见光图像的背景部分和细节部分分别进行融合后,再送入解码器进行图像重建,得到融合结果。

为了避免细节信息损失,在网络中加入short connection,分别将编码器的前两个卷积层输出特征图与解码器后两个卷积层输出的特征图进行直接拼接。编码器输出的背景特征图和细节特征图需要通过训练得到,因此设计了相应的损失函数。 损失函数各项包括编码器损失L1(Figure 1(a) \(L_{total}\) 中的前两项)和解码器损失L2(\(L_{total}\)的后三项)。L1用于图像分解,希望两种模态背景部分相差较小、细节部分相差较大,因此第一项和第二项分别为正、负。经过tanh函数,可以将二者的差距限定在-1到1之间。L2用于图像重建,第三、四项目的是保持源图像和重建图像的像素幅度信息和细节纹理信息,很多2020年的自监督模型都是通过这种损失函数来训练网络的,用的是非常普遍的L2-norm和结构相似度SSIM,分别计算红外源图像与重建图像之间的损失、可见光源图像与重建图像之间的损失。具体形式如下:

损失函数最后一项使用梯度算子来保留可见光图像的细节信息。自监督模型在计算纹理细节损失中,使用SSIM和梯度算子很普遍。
5.DDcGAN
A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion (Transactions on Image Processing, 2020)
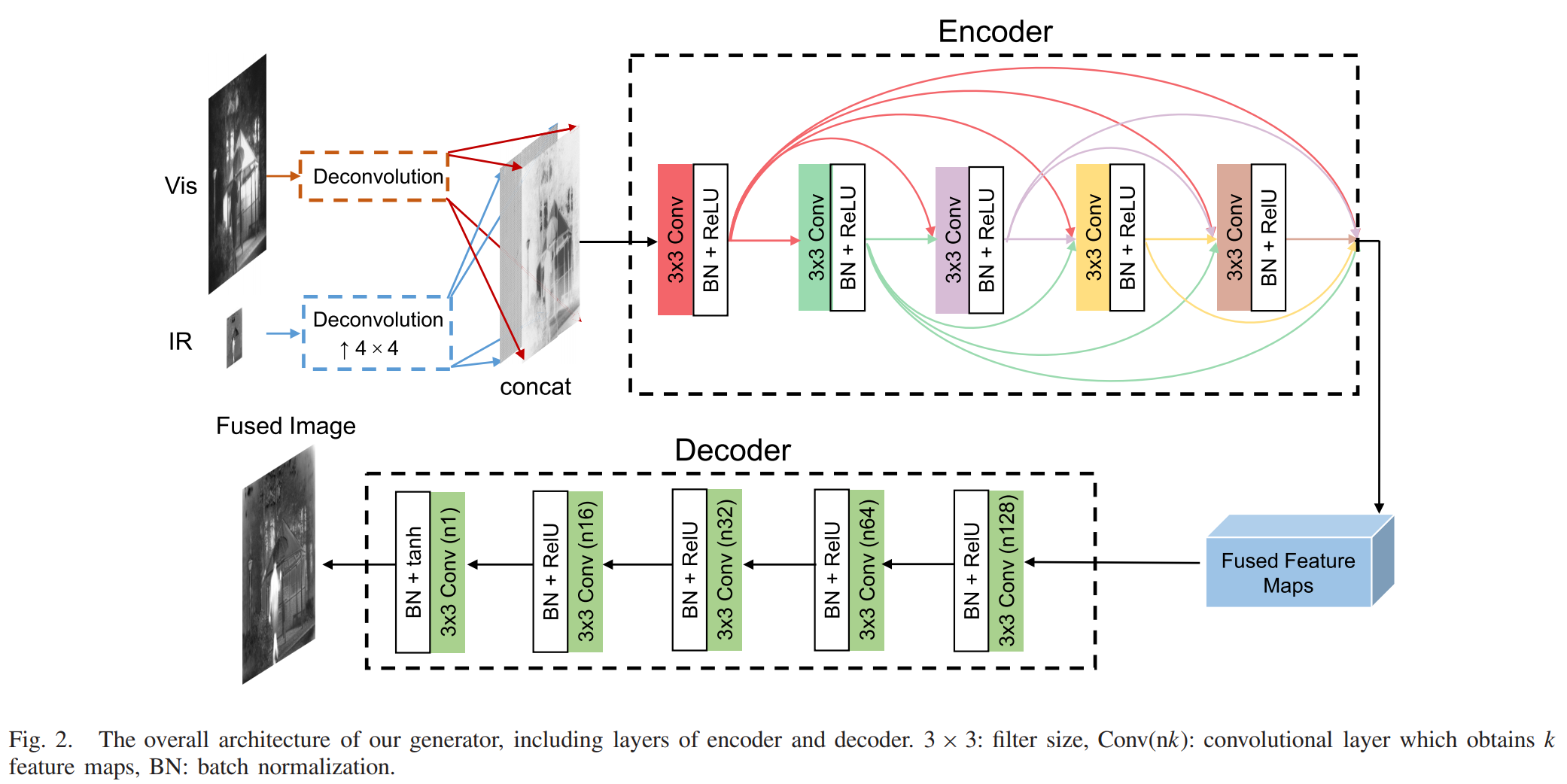
是2020年的GAN模型之一,融合效果在细节和对比度方面要优于FusionGAN,并且是针对红外图像分辨率低于可见光图像分辨率的情况。模型首先通过训练过的卷积层对分辨率低的红外图像进行上采样到可见光图像的分辨率(也可以将融合与超分一起做,具体的模型看CF-Net),然后生成器对这两张图像进行融合,两个判别器分别针对红外与可见光图像进行判断。损失函数方面和先前模型类似,都是基于保留红外图像像素幅度、可见光图像细节信息的基础上设计的。

生成器的结构如下图,首先通过反卷积层将红外图像上采样到和可见光图像一样的尺寸(红外图像训练集手动下采样到原图的1/4大小),两张图像在通道维度拼接后送入5个加入dense connection的编码层,再经过5个常规卷积层就能得到融合图像了。
判别器的结构如下图,红外图像和可见光图像各一个判别器。红外图像对应的判别器是从融合图像或红外原输入图像中随机选出一张作为输入,可见光图像对应的判别器是从融合图像或可见光原输入图像中随机选出一张作为输入,它们的输出都是一个代表概率的标量,表示输入图像是真实图像(原图)的概率。

编码器的损失函数是由adversarial loss和content loss组成,其中Content loss中红外图像的像素幅度计算通过Frobenius norm得到,而可见光图像的细节信息通过TV-norm得到。判别器的损失函数用于区分源(原)图像和融合图像,判别器的adversarial loss可以用来计算不同分布之间的Jensen-Shannon差异,因此可以用来判断像素强度和纹理细节分布的真实性并促使融合图像的分布更贴近真实分布。
6.Fast-UIF
Rethinking the Image Fusion: A Fast Unified Image Fusion Network based on Proportional Maintenance of Gradient and Intensity (AAAI, 2020)
这是用于通用融合任务的模型,进行不同融合任务时需要调整损失函数中各项的权重。网络整体分为gradient path和intensity path两个分支,输入则是不同模态的混合输入,而非先前模型采用的gradient输入可见光图像(细节信息多的模态),intensity输入红外图像(像素幅度信息多的模态),在进行最终的融合前还有预融合模块。
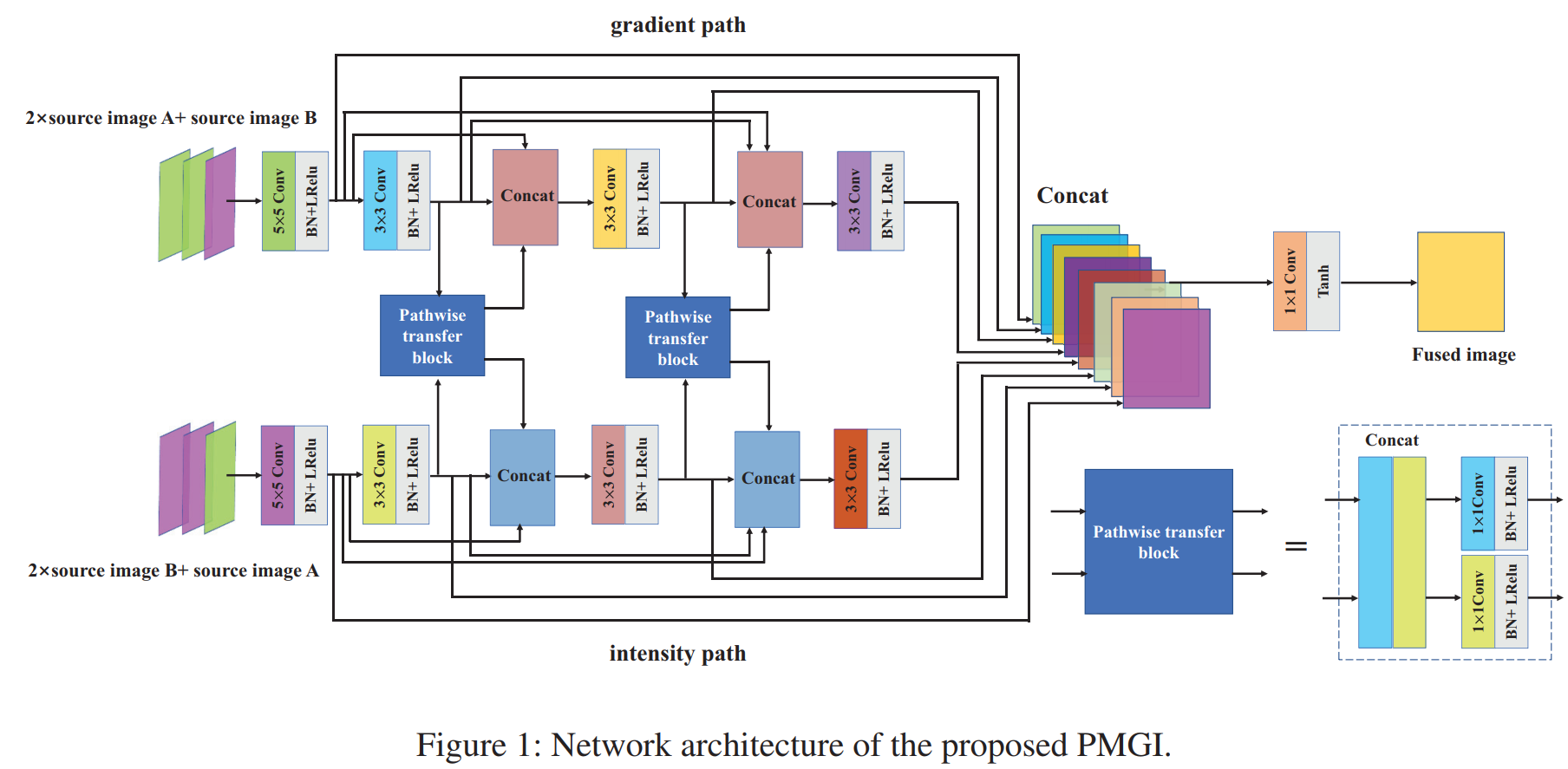
Gradient path的输入由两张可见光图像和一张红外图像组成,intensity path的输入由两张红外图像和一张可见光图像组成,也可以根据场景调整两个模态图像的比例。两个分支都是由卷积层组成,不包含下采样步骤,并且各自包含两次通道维度拼接过程和两个预融合模块(pathwise transfer block),最后每个卷积块的输出都会全部进行一次通道维度的拼接,经过单层卷积后是最终的融合图像。损失函数的设计以像素幅度项与梯度项为主,不同的融合任务调整四个项的权重即可,比如红外与可见光的融合中红外图像包含的幅度信息多,所以计算像素幅度的项:红外对应的那一项权重应该大于可见光的;同理,计算梯度的项:可见光对应的权重应该大于红外的。
7.FusionDN & U2Fusion
FusionDN和U2Fusion的融合思想是一样的,FusionDN作者先发表在AAAI(2020)上,后来作者将改进后的U2Fusion发表在了TPAMI上。
两篇文章都是对融合过程中每种模态图像信息量的测量与保留方法进行了研究,FusionDN通过已有的图像质量评价模型NR-IQA和熵Entropy的计算来测量每个模态图像的信息量得到权重,而U2Fusion通过Feature Extraction、Information Measurement、Information Preservation Degree三个模块根据源图像直接得到其相应的信息量权重,作用就相当于FusionDN的NR-IQA和Entropy,其中Feature Extraction使用的是预训练的VGG-16,在大量数据上预训练过的深度网络可以提取出图像中各类特征。信息权重作用于损失函数。另外,U2Fusion在损失函数中加了EWC(Elastic Weight Consolidation, 可塑权重巩固, 点击查看详细解读)这一项,避免网络串行训练数据时遗忘先前的任务内容。融合网络比较简单,将两个输入在通道维度拼接后送入卷积层就OK了。
详情可以点击以下链接查看:
8.FusionGAN++
Infrared and visible image fusion via detail preserving adversarial learning (Information Fusion, 2020)
本文的模型用于改善先前GAN模型带来的细节损失问题,并且加入了针对边缘的保护机制。模型的生成器产生融合图像,然后将融合结果与可见光源图像一起送入判别器,判断融合结果是否来自于可见光图像。当判别器不能区分融合结果与可见光图像时,此时认为融合结果包含了充足的细节信息,通过这种方式就能自动进行细节信息的表示和选择,不再通过人工设计融合规则。边缘保护体现在损失函数中。
9.RFN-Nest
An end-to-end residual fusion network for infrared and visible images (Information Fusion, 2021)
RFN-Nest在2020年NestFuse的基础上,将融合模块从人工设计的融合规则变成了用网络进行融合,同时不再是单独用自然图像进行有监督训练,也和很多其他模型类似,加入了自监督学习方法,其中第一阶段训练和NestFuse一样,用大量自然图像训练一个自编码器,而第二阶段训练是RFN-Nest新增加的自监督训练方式,会生成四个用于多尺度融合的RFN(Residual fusion network)模块。相较于其他自监督模型的不同之处是多尺度(很多融合模型为了避免细节损失不会使用任何下采样步骤)和大规模红外-可见光数据集参与了训练。
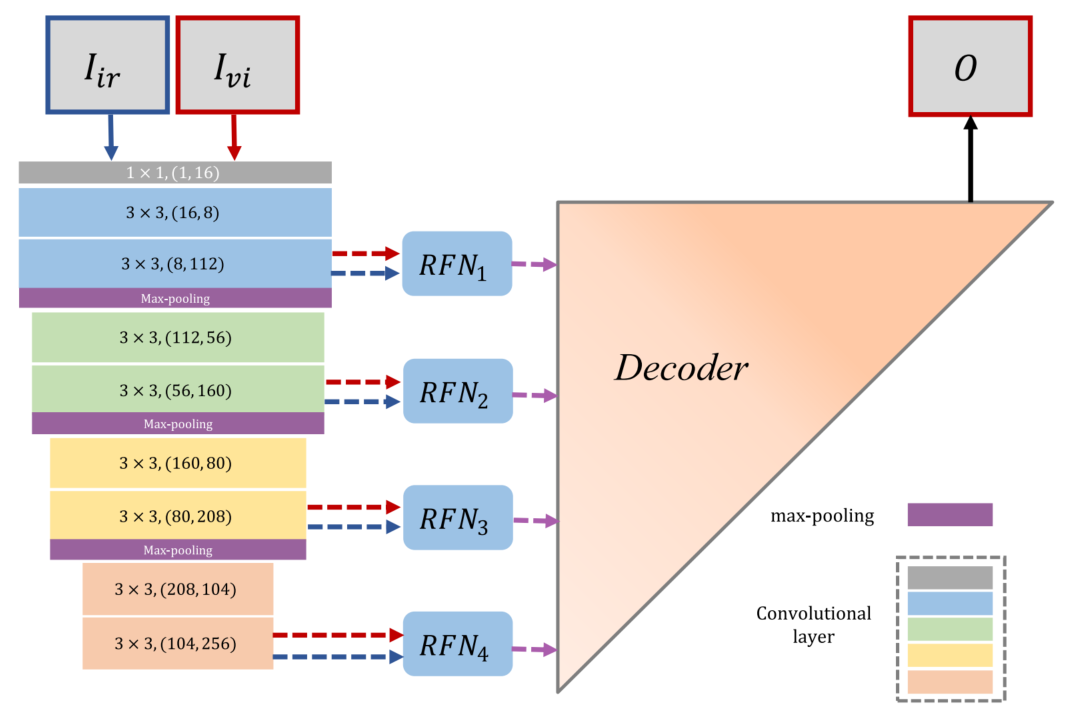
首先来说第一阶段训练,编码器和解码器与先前的NestFuse相同,并且第一阶段训练也仍然是用自然图像训练自编码器,采用的是COCO数据集的八万张图像。
第二阶段是训练四个RFN模块,其实也就是学习融合策略,需要先将编码器和解码器的网络参数都固定(相当于RFN的输入输出固定),然后用自监督方法专门训练该模块的网络。RFN结构如下:
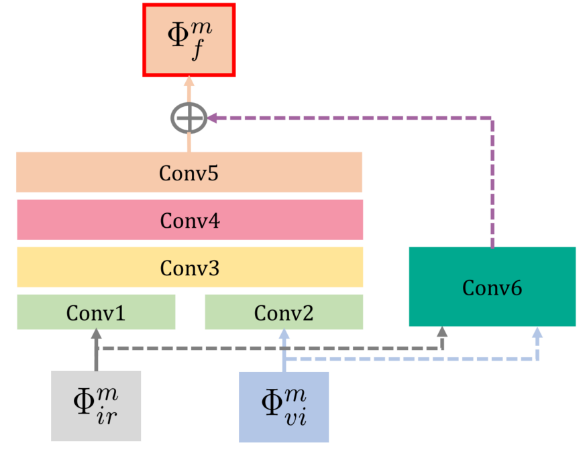
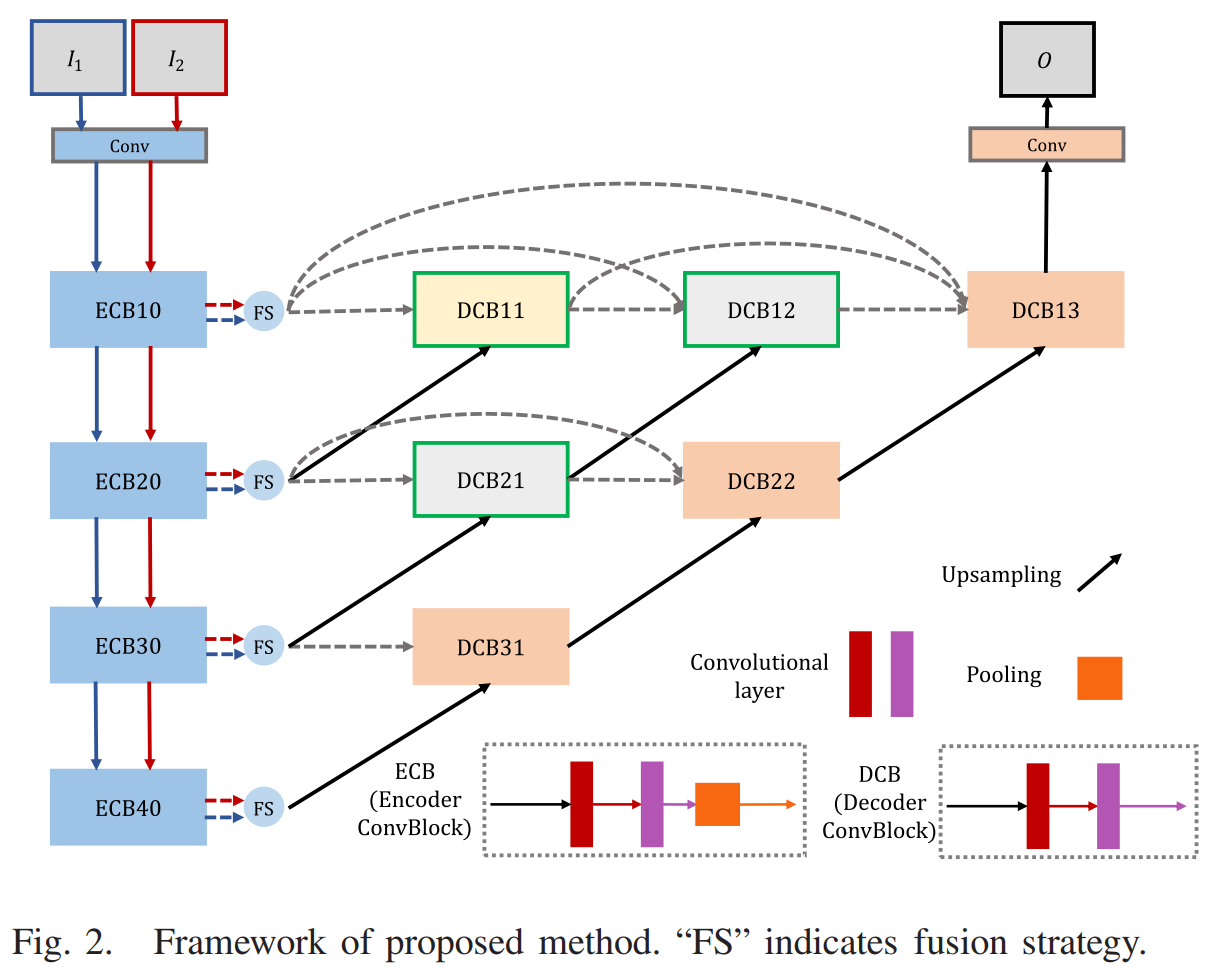
两个模态的特征图会分成两个分支,一个分支各自经过单个卷积层后在通道维度拼接,再用后续三个卷积层处理,另一个分支则经过单个卷积层后作为残差连接和另个分支的组合,得到的就是融合特征图。四个RFN模块均为这种结构,在四个尺度上对特征图进行融合。这阶段训练使用的数据集为KAIST数据集,包含八万个红外-可见光图像对。
10.CF-Net
Deep Coupled Feedback Network for Exposure Fusion and Image Super-Resolution (Transactions on Image Processing, 2021)
本文提出的CF-Net是将超分和多曝光融合用一个网络做的端对端模型,这种多任务图像融合模型也是综述Image fusion meets deep learning: A survey and perspective中提出的图像融合趋势。超分辨有利于目标检测的准确度,因此如果把多曝光任务和超分辨率任务一起做,应该也可以提高high-level的任务效果,因此CF-Net也可以认为是任务驱动的融合模型,即未来的发展趋势之一。
查看详情:红外与可见光图像融合模型总结3.2
11.STDFusionNet
An Infrared and Visible Image Fusion Network Based on Salient Target Detection (Transactions on Instrumentation and Measurement, 2021)
STDFusionNet是基于显著性目标检测的融合方法,可以保护红外显著性目标的纹理信息和温度信息。首先用mask对红外显著性目标进行标注,然后结合mask设计损失函数来进行提取特征和重建。mask只在训练阶段使用,也就是说本文模型可以隐式完成显著目标检测和关键信息融合。应该说STDFusionNet也考虑了红外与可见光融合的互补信息,只不过人为地将其定义为红外图像的显著目标和可见光图像中的背景纹理的组合。
网络结构如下图,可以看到网络的输入是完整的图像,只不过在计算损失函数时会用mask对红外图像中的显著性目标单独提出来,将可见光图像的背景区域单独提出来计算相应的损失。两个模态的特征图也是在通道维度拼接后送入图像重建网络中的。
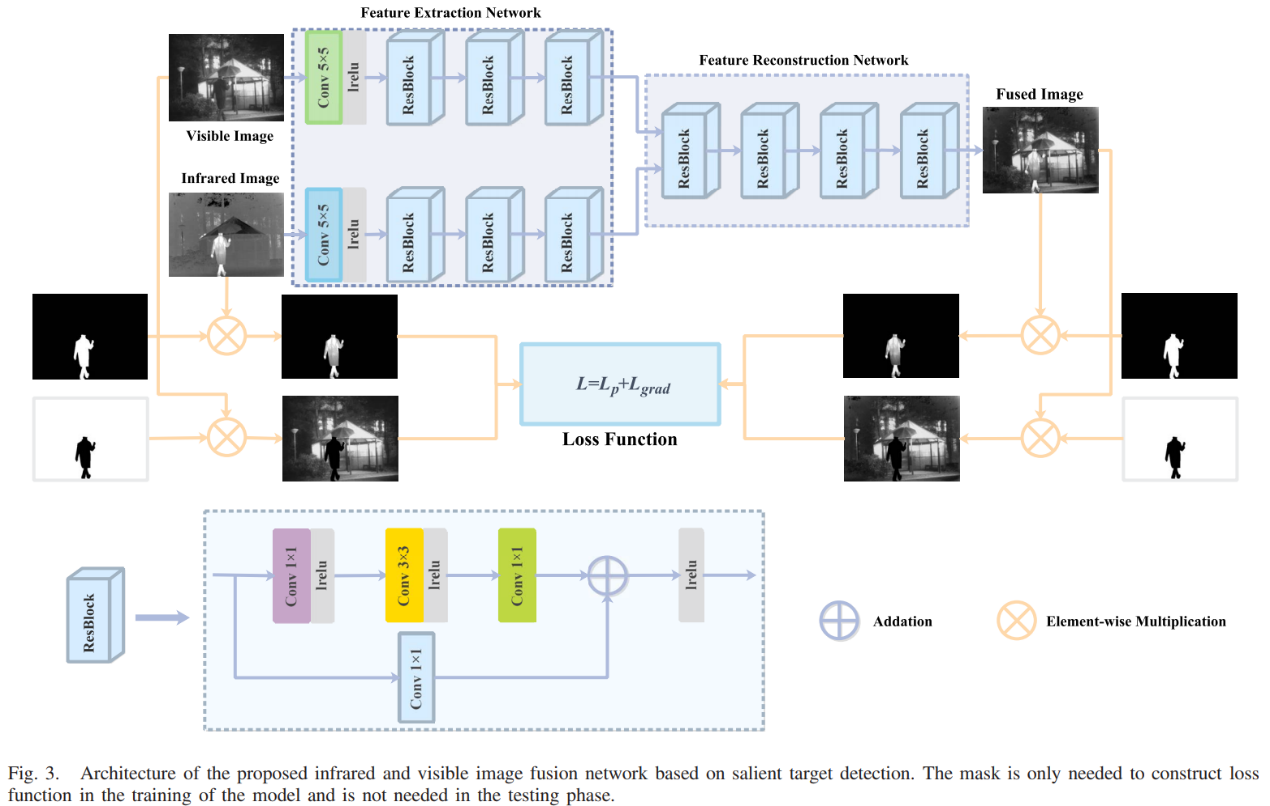
损失函数:

12.CSF(Saliency-based)
Classification Saliency-Based Rule for Visible and Infrared Image Fusion (Transactions on Computational Imaging, 2021)
本文也提出了一种基于显著性分类的融合方法classification saliency-based fusion method (CSF),不过和上一个STDFusionNet在图像内选择显著性区域不同,本文的模型是根据多个卷积层输出特征图的可解释性重要性来评估的,这种面向重要性的融合规则有助于保留有价值的特征图,得到的显著性信息就直接作为融合的加权系数。首先使用分类器对两种类型的源图像进行分类,可以测量源图像之的差异信息和独有信息。然后根据每个像素对分类结果的贡献程度计算它的重要性,该重要性将以分类显著图的形式呈现,根据这个分类显著图来融合各个特征图,这种通过预训练过的分类器来自动保留重要特征也是一个新颖的角度。
整体结构如下图,和其他深度学习模型一样,先提取特征图进行融合,然后对融合特征图进行重建。特征提取和重建都是普通的卷积层,重点就在于融合特征图这部分的设计,也是本文的核心。
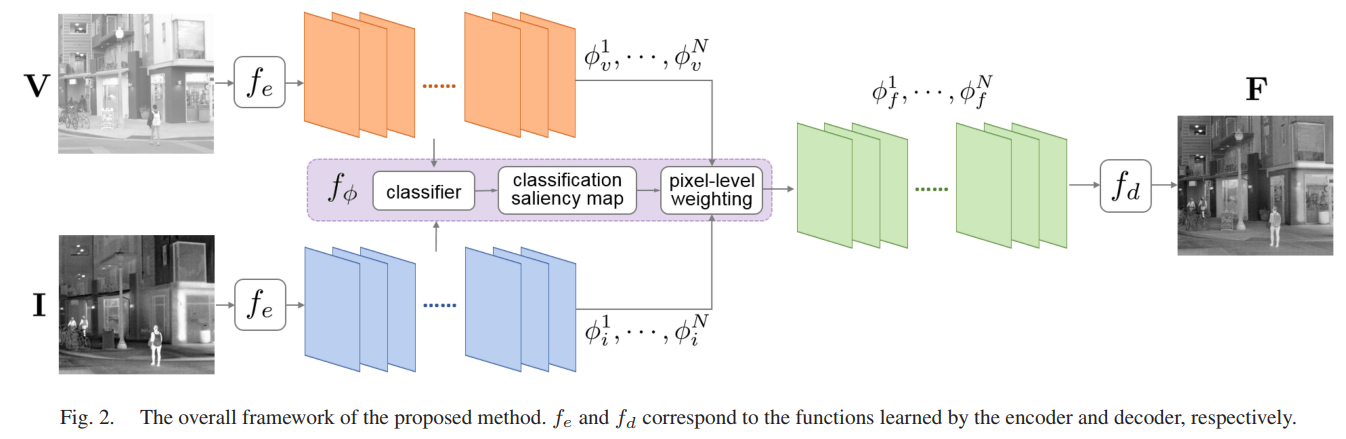
分类显著性估计(Classification Saliency Evaluation):红外与可见光图像融合的一大策略就是将每个模态下图像的重要信息和互补信息提取出来进行融合,因此该融合的关键点就在于特征图每个区域的重要性评估,重要的区域需要被保留,冗余区域需要被压缩。
一种直观的评价方式是将部分可见光特征图替换为红外特征图,然后观察替换后结果的变化。如果这部分是多余的,在替换之后,重建的图像仍然会看起来像原始的可见光图像。如果不是多余的(这部分包含红外图像中的唯一/关键信息),替换后重建的图像将与红外图像相似。反之亦然。为了量化图像风格,使用一个二分类器测量图像属于任何一种风格的概率。此外,分类器能找到每种风格最明显的特性和不同风格之间最明显的差异,可以比较不同类型的信息并帮助识别重要且值得保留的信息,这种功能对融合很有用处,所以使用分类器来帮助定量设计融合规则。
上述思想的具体实现方法:以图像对为例进行通道替换。当24张输入的特征图全部都是红外特征图时,该特征图组被判断风格为红外的概率接近1,而将这组中的其中一张特征图替换为可见光图像特征图,再看风格被判断为红外的概率是多少。用这种方法,按照顺序依次将24张特征图的某一张替换为可见光特征图,概率值的变化就可以统计出来了。
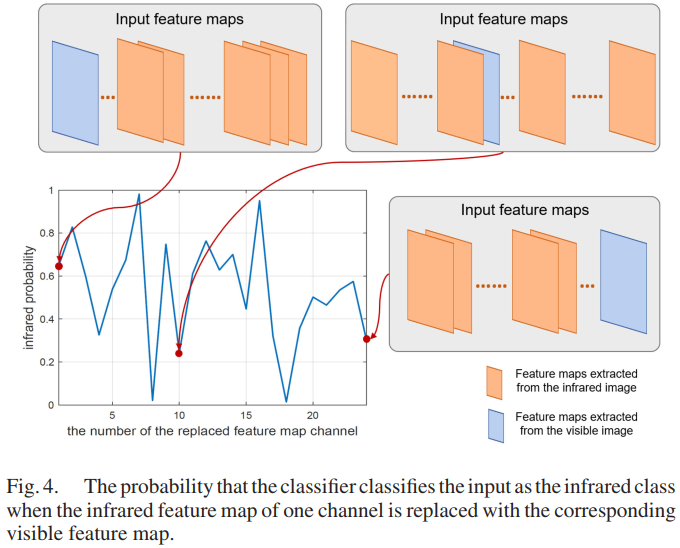
上图中有一些位置特征图被替换后,风格被判断为红外的概率大大降低,有的则基本没有下降,可以说那些被替换后概率没有下降太多的特征图,对于分类的贡献就不是很大,也就是说这个位置的特征图对分类没什么作用,即红外和可见光在这个通道位置上对应的特征比较一致,没有较大的区分度。相反地,一些位置的特征图被替换后,风格被判断为红外的概率大大降低,这些位置可以说对分类的贡献较大,红外和可见光在这些位置上的特征差异较大。根据特征图对分类结果的影响,可以评估重要性以反映这些特征图是否包含重要信息,将其称为分类显着性(classification saliency),以此作为融合时信息量保留的基础。
上面所说的是通道维度上的显著性,即channel-wise。在每个特征图上的每个像素也存在显著性差异,即pixel-wise,因此需要综合看待每个特征图上的单个像素对分类器判断为红外或可见光图像中概率较大的那个值的变化,从而计算出每个像素位置上的显著性值,即分类显著性图。
有了这两个权重图,下一步和先前NestFuse模型一样,每个模态的特征图和权重图相乘再相加即可。
另外,文中有一段阐述了现有人工设计融合方式的缺陷,写的很好:
The reason why existing fusion rules are rough for fusing features is as follows. Because of the unexplainability and incomprehensibility of CNNs, the specific characteristics represented in feature maps are unknowable. For instance, some convolution kernels extract bright regions, some extract dark regions while some may extract lines. If this is the case, the max rule can well preserve the bright regions while the information with low brightness will suffer from distortion. Because of the unknown and variability, it is difficult to measure the importance of different regions of feature maps. Thus, it is groundless to design a fusion rule by assigning pixel-wise weight maps, which take the pixel-wise importance of feature maps into account. In this case, the limited choices of fusion rules and their roughness restrict the improvement of fusion results. Even a well-designed feature extraction way may fail to achieve its optimal performance because of the restriction of the fusion rule.
13.GANMcC
A Generative Adversarial Network With Multiclassification Constraints for Infrared and Visible Image Fusion (Transactions on Instrumentation and Measurement, 2021)
以往提起红外与可见光图像,一般都认为红外图像细节差,但是目标显著性好、对比度高,要用像素幅度约束;可见光图像细节好,要用梯度或SSIM约束。GANMcC提出的思想是,红外图的细节不一定就比可见光差,可见光也有可能对比度优于红外图像,而在某些场景下确实如此。
此外要确保融合图像既有显著的对比度又有丰富的纹理细节,关键是保证源图像的对比度和梯度信息是平衡的,本质上是同时估计两个不同域的分布,GAN可以在无监督情况下更好地估计目标的概率分布,而多分类GAN可以进一步同时拟合多个分布特征,解决这种不平衡的信息融合。
具体做法是:用一个多分类器作为判别器,可以确定输入是红外图像和可见图像的概率。对于融合图像,在多分类约束下,生成器期望这两个概率都很高,即判别器认为它既是红外图像又是可见光图像;而判别器期望这两个概率同时很小,即判别器判断融合图像既不是红外图像也不是可见光图像。在此过程中,同时约束这两个概率,以确保融合图像在两个类别中的true/false程度相近/相同。经过不断的对抗学习,生成器可以同时拟合红外图像和可见光图像的概率分布,从而产生对比度显著和纹理细节丰富的结果。通过这两种设计的配合,可以生成具有良好视觉效果的融合图像。模型结构如下图所示。
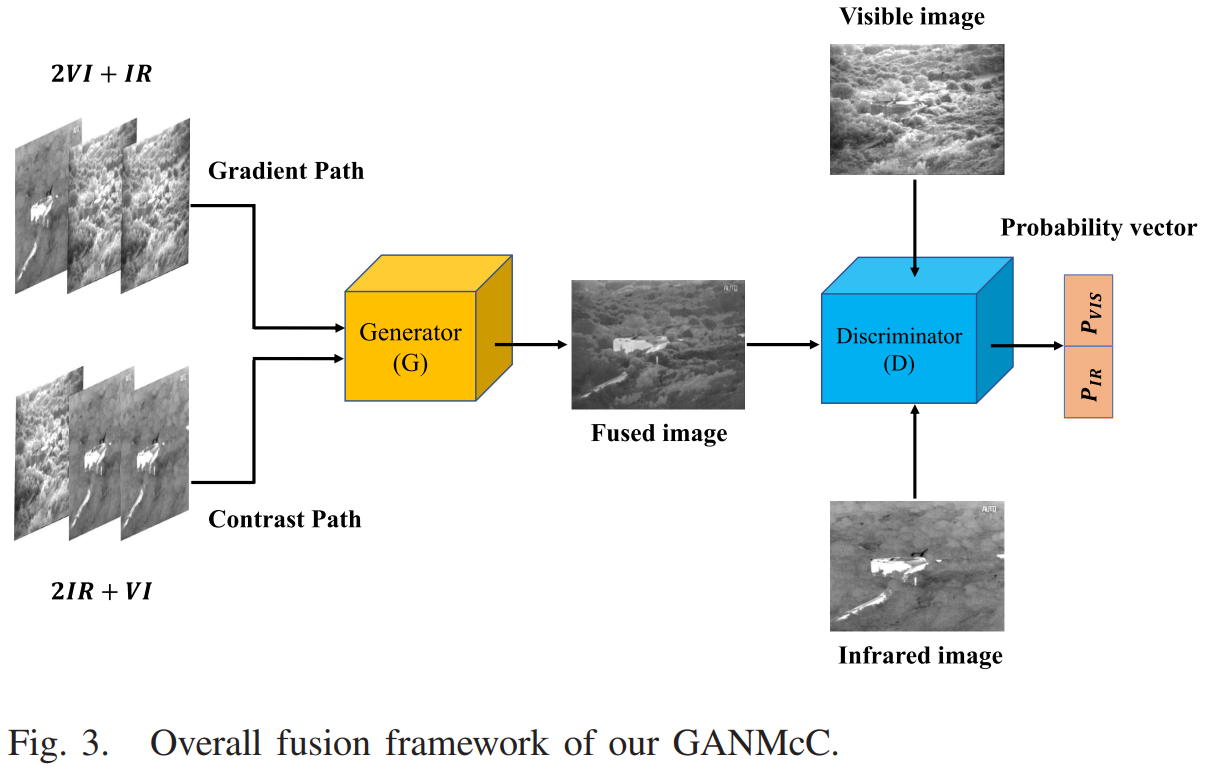
输入与上述第6个网络Fast Unified Image Fusion Network一样,也是两个模态的混合输入,由生成器得到融合图像,判别器输出该融合图像属于红外/可见光的两个概率值,多轮对抗训练后,当两个概率值都比较大的时候,认为互补融合信息达到了平衡。
生成器的结构如下,其中在拼接特征图时是将两个分支特征图交叉拼接的,目的是为了更好融合信息。
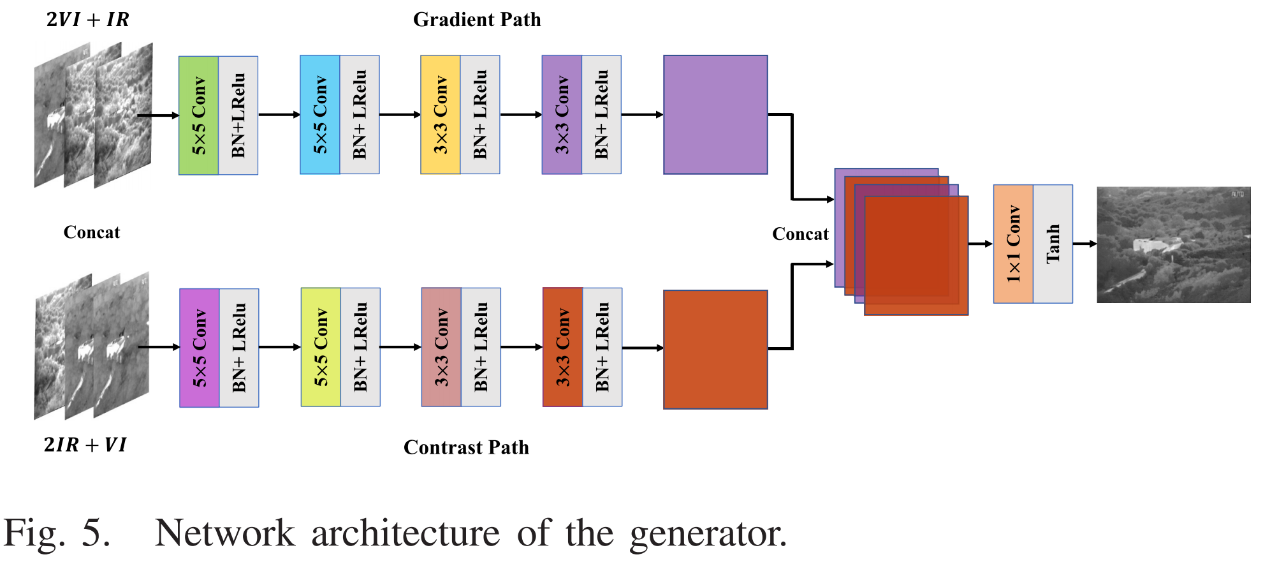
因为使用了GAN网络,故损失函数包含content loss和adversarial loss两项,而本文模型的思想是红外图像也有细节信息,可见光图像也有较好的对比度,因此content loss的设计考虑了辅助信息,也就是红外图像的纹理细节与可见光图像的对比度信息。通过调整每一项损失的权重大小来决定每种信息的保留程度,首先主要信息的权重应该大于辅助信息的权重,并且梯度信息的权重一般要小于像素强度信息的权重。按照这个规则进行权值的设置。
判别器的结构如下,判别器也是一个多分类器,对输入图像(红外/可见光/融合图像任选一个输入)进行分类得到输入图像的类别,输出是一个包含两个概率值的向量。

损失函数必须促使判别器不断提高其判别能力,才能有效地识别出什么是红外图像或可见光图像。损失函数由三项组成,分别为可见光图像、红外图像、融合图像的decision loss。具体的损失函数设计就不摆在这里了,可以查看作者论文原文或者专栏第3.7中的内容。
14.RXDNFuse
A aggregated residual dense network for infrared and visible image fusion (Information Fusion, 2021)
RXDNFuse是在融合网络中加入残差连接的模型,对损失函数也有一定的改进,分为像素级损失和特征级损失,像素级损失还是以像素幅度和结构相似度为基础计算的,特征级损失则是以VGG-19提取的深度特征图作为基础。
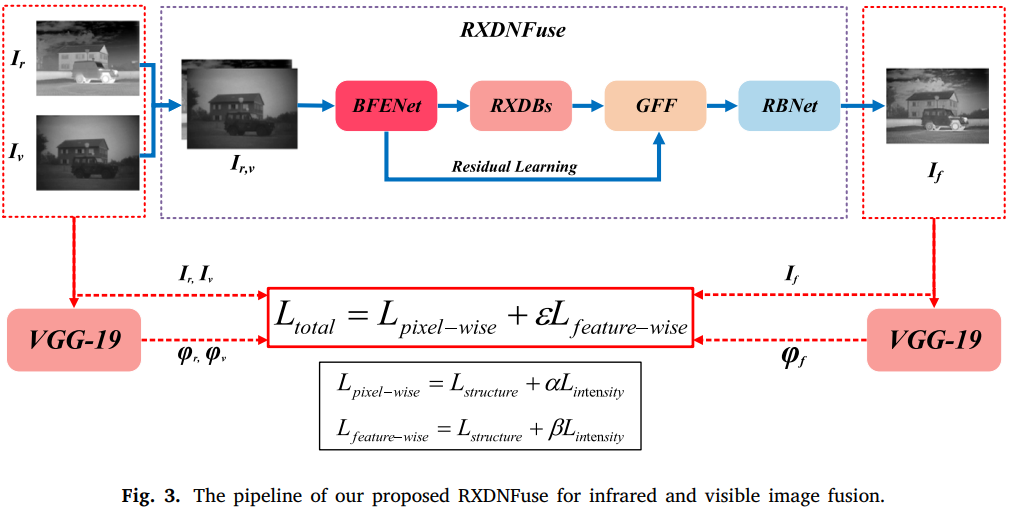
这里知识简单说明文章的中心思想,网络子结构主要是添加了残差连接和密集连接,idea在损失函数方面要更多一点。
像素级损失的结构损失和像素幅度损失计算如下图,融合图像与红外、可见光源图都会进行像素幅度和SSIM的计算。

特征级损失其实就是perceptual loss,同样也需要分别计算结构损失和像素幅度损失。而使用深度网络特征图来计算损失的原因作者也引用了其他文章中的结论:通过深度神经网络对图像特征进行逐层处理,输入图像会转换为对图像实际内容越来越敏感的抽象表示,如果直接用较浅层的特征图进行重建,其实只是简单地将原始图像的每个像素进行了重现,与之相反的是深层特征可以捕获抽象语义特征。因此这里将每个输入图像复制为三个通道后送入VGG-19模型来提取高级(深层次的)语义特征,如下图所示。
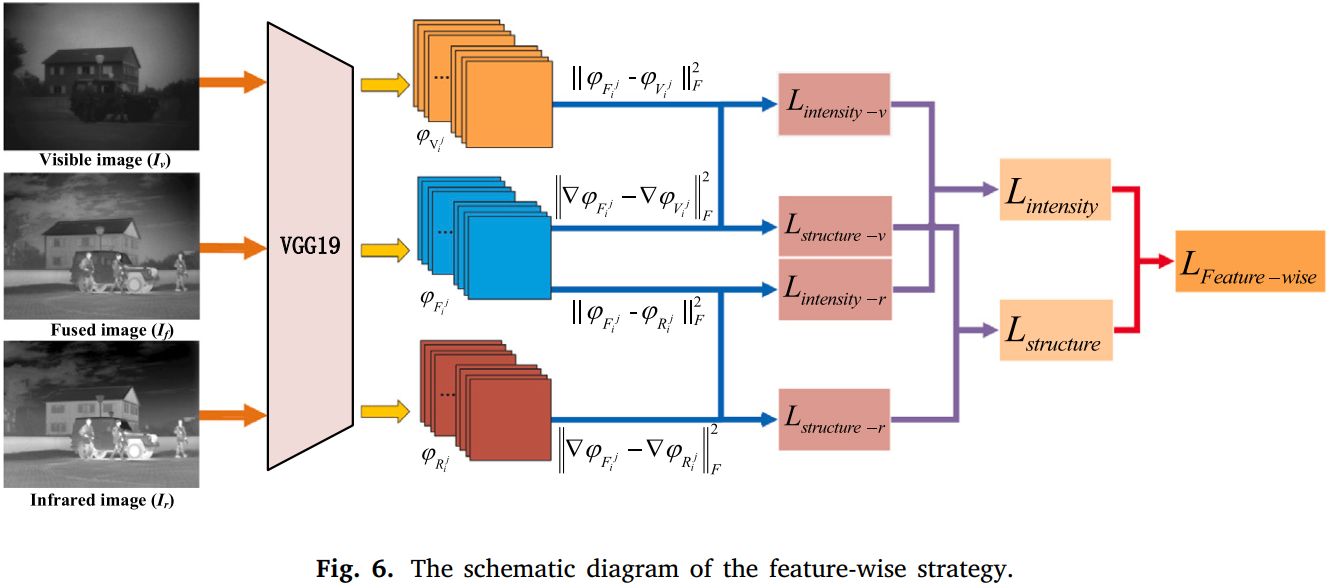
感知损失是论文Perceptual Losses for Real-Time Style Transfer and Super-Resolution中提出的概念,用于实时超分辨任务和风格迁移任务,后来也被应用于更多的领域,如图像去雾。下面是论文的解读和损失函数说明的链接。
这篇文章到这里就结束啦!
本文总结了《部分基于深度学习的红外与可见光图像融合模型总结》3.8及以前的内容,3.9之后的内容和别的文章将在本系列(二)中进行更新,内容涉及:部分传统方法、更新的Paper等,敬请期待~