文献整理 · 脉络篇(二)
Last updated on May 12, 2024 pm
1.TC-GAN
Infrared and Visible Image Fusion via Texture Conditional Generative Adversarial Network (Transactions on Circuits and Systems for Video Technology, 2021)
本文模型TC-GAN的一大亮点是使用了引导滤波器,引导滤波器首次于2013年由K.He, J.Sun, and X.Tang提出,可以充分利用相邻像素之间的相关性,让图像包含特定的一致性。具体原理是引导滤波器会用一个引导图像Y来对输入图像X进行滤波,输出图像Z便能在保持X信息的基础上获得引导图像Y的变化趋势。
TC-GAN会生成一个组合纹理图来捕获梯度变化。生成器是编码器结构,用来提取细节,中间有一个SE-Net模块来提高纹理图中显著纹理信息的权重。判别器的作用是让融合图像的纹理细节更接近可见光图像。为了获得更好的纹理信息,作者们提出了一种使用组合纹理图和自适应引导滤波器的基于多决策图的融合策略。换句话说就是:组合纹理图记录了原图像的纹理,被用作自适应引导滤波器(AGF)的引导图像,然后采用AGF生成的多个决策图来设计融合策略重建融合结果。
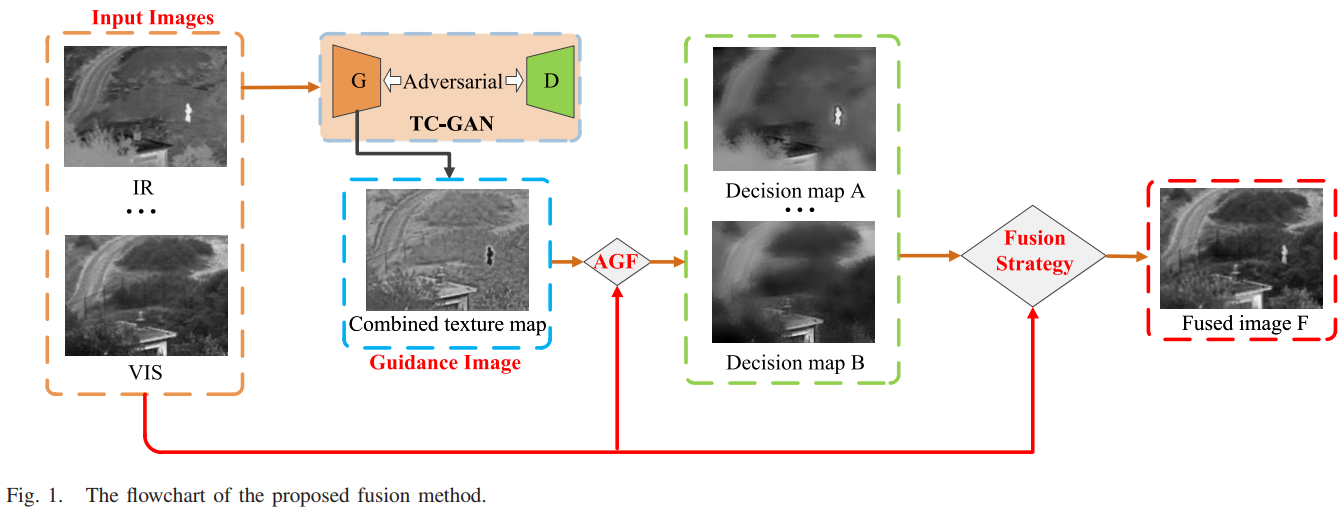
首先红外与可见光图像会一起送入TC-GAN中生成组合纹理图,然后组合纹理图会被作为引导图像,用引导滤波器对源图像进行滤波,获得多个决策图。最后用多个决策图融合并重建图像。其中TC-GAN的具体结构如下图。
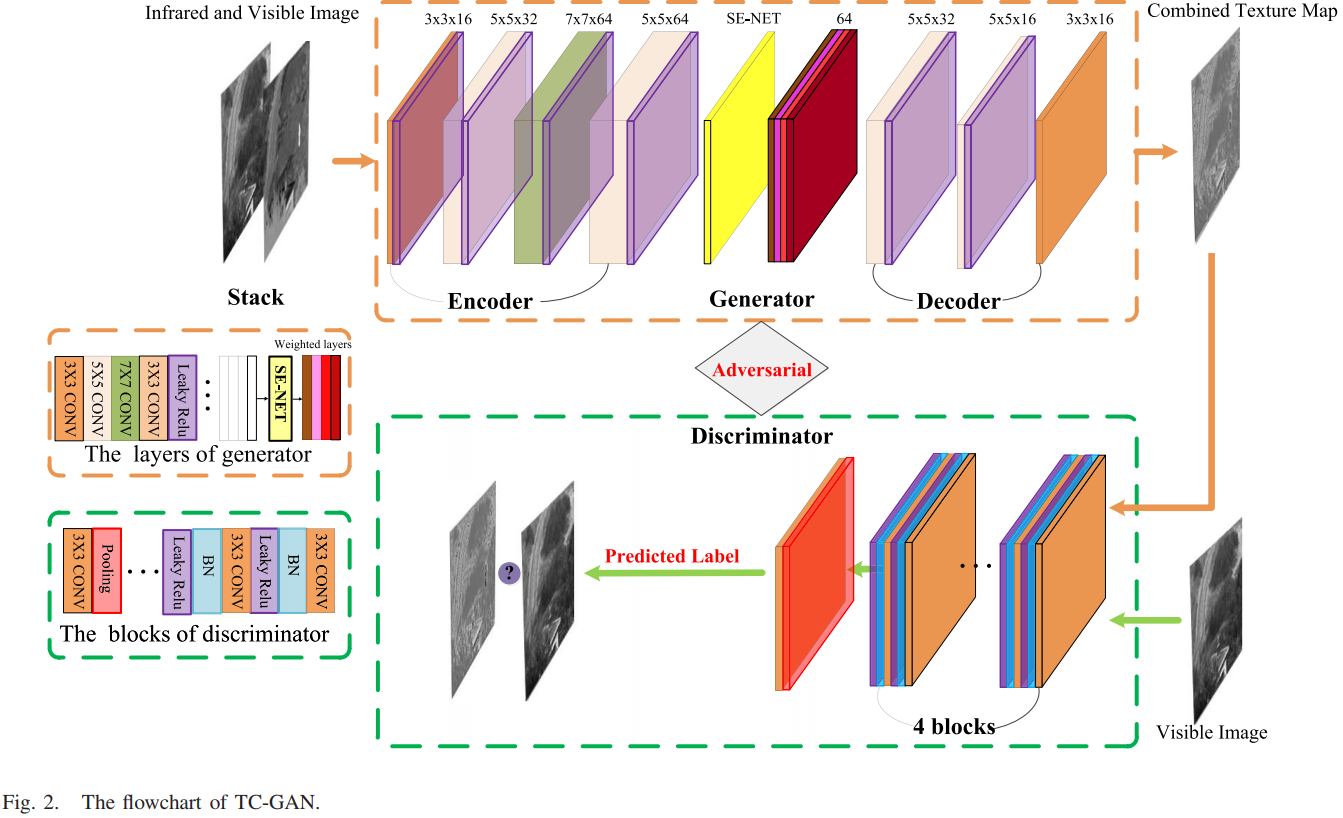
生成器由编码器、SE-Net、解码器三部分组成。中间的SE-Net模块学习到的尺度向量对编码器提取的特征进行加权,可以在训练过程中增强有用的纹理特征,因此用在编码器后面来增强特征。要生成组合纹理图,需要在组合纹理图的监督下训练生成器,然而组合纹理图并不存在(还没生成呢)。因此本文是采用GAN的训练模式,定义了一个判别器,以包含丰富纹理细节的可见光图像作为标签来训练生成器。判别器是一个全卷积网络,对图像进行像素级别的分类,可以判断生成图像中的纹理分布是否与可见图像的纹理分布一致。
损失函数的设计:生成器损失函数包含gradient loss和adversarial loss两个部分,梯度损失是为了让生成的纹理图包含更多的细节,将对抗损失和梯度损失加权求和得到生成器的损失。判别器引导TC-GAN生成器的训练来识别融合图像与可见光图像,促使生成器得到的融合图像包含更多纹理细节,因此判别器利用交叉熵作为损失来计算融合图像与可见光图像之间的差异。
对抗损失adversarial loss在所有用GAN模型的文章中都出现了,建议回顾相关资料附上CSDN关于对抗Loss理解的文章链接:对抗Loss的理解
在经过TC-GAN获得组合纹理图作为引导图像对源图像进行滤波后,可以获得多个决策图,下面就是对这些决策图进行融合了。多决策图的融合包含两个步骤:1.基于组合纹理图创建多个决策图(组合纹理图作为引导滤波器的引导图像);2.多决策图被用于获得初步的融合结果。最终的融合图像是通过加权法获得的。
2.AttentionFGAN
Infrared and Visible Image Fusion Using Attention-Based Generative Adversarial Networks (Transactions on Multimedia, 2021)
AttentionFGAN将多尺度注意力机制加入GAN来进行红外-可见光图像的融合。对于判别器,优势主要是可以限制判别器对注意力区域关注得更多,而非全图都关注;对于生成器,多尺度注意力网络被用来训练学习一个特征的权重,使重要特征被赋予更多注意,冗余特征则被忽略。为了保留注意力区域更多信息,设计了attention损失函数。判别器改用Wasserstein distance计算源图像和融合图像之间的差异。从结果来看AttentionFGAN对红外显著性区域保护的很不错。
模型的结构如下图。生成器包含2个多尺度注意力网络和1个融合网络,两个多尺度注意力网络分别获得红外与可见光图像的注意力图,融合网络在重建图像时会更关注重点区域。2个判别器会让融合结果更好地保留像素幅度与细节信息,作用分别是区分融合图像与红外/可见光图像。
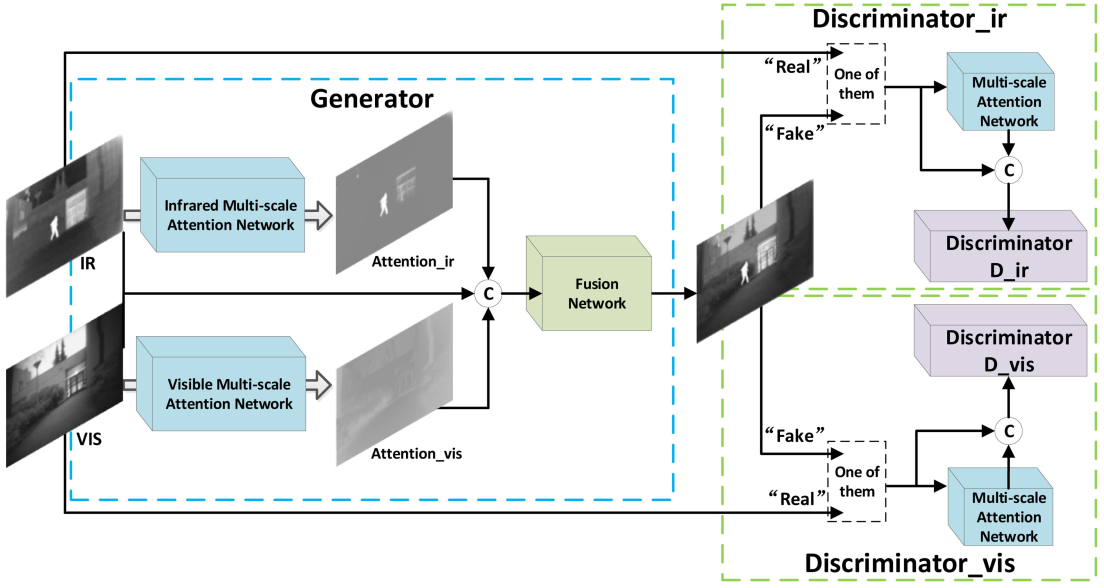
生成器部分的两个多尺度注意力模块首先分别获得红外与可见光图像的注意力图,然后将这两个注意力图和源图像在通道维度拼接后送入融合网络。两个判别器分别用来区分融合图像与红外/可见光图像,结构完全相同,但是参数不共享。在训练阶段,将输入图像(融合图像)送入多尺度注意力网络计算注意力图,然后将注意力图和输入图像在通道维度拼接,让判别器能更关注具有区分力的区域。为了提高效果,这里用了WGAN中的Wasserstein distance来计算融合图像与源图像之间的距离。由于WGAN是专门计算Wasserstein distance的,可以看做为一个回归问题,因此在计算损失的时候将log函数去除了,判别器最后一个sigmoid层也被移除了。
上图中的多尺度融合网络,在生成器中的作用是获得注意力图,在判别器中的作用是让模型更关注具有判别能力的区域,它的结构如下图。
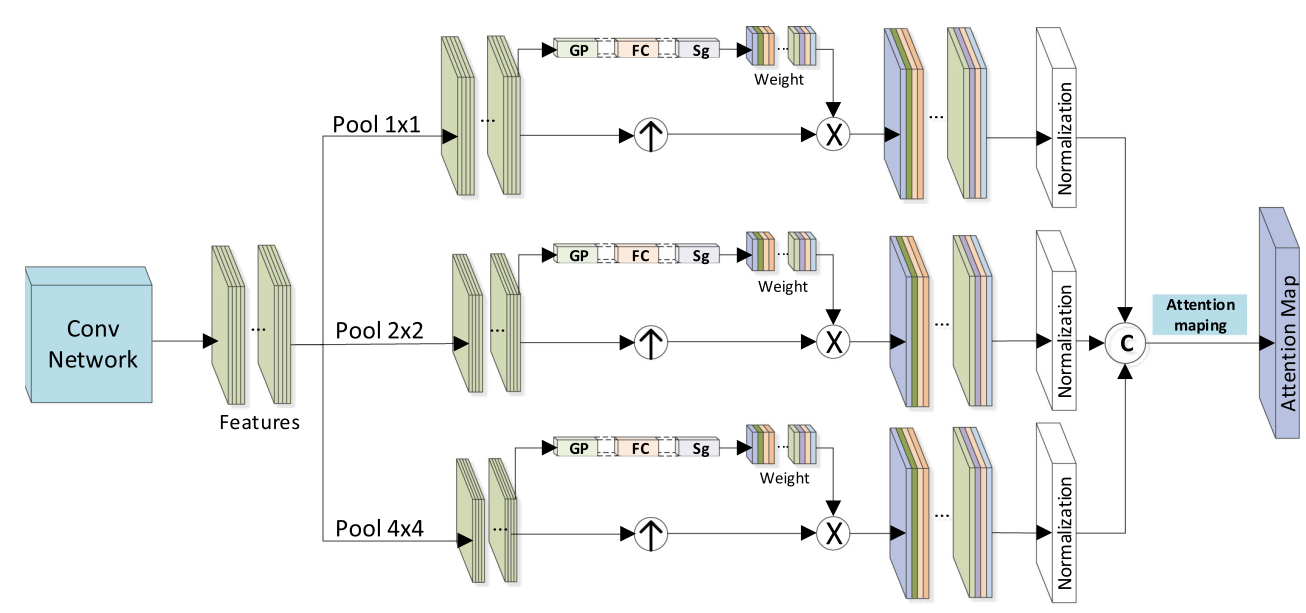
首先使用卷积层提取特征,这里用最后两个卷积层的输出作为深层特征图。单尺度的特征难以提取到有效的空间信息,因此通过多个尺寸的全局池化来获得多尺度特征。但是在池化操作会产生太多冗余特征图,最好是选择重要特征,去除冗余特征,所以这里让网络基于每个特征图的全局信息来重新计算权重。这个过程由GP+FC+Sg三个模块实现。全局池化GP结束后用全连接层和sigmoid来计算权重。
获得了最终的权重后,用上采样算子对多尺度特征图进行上采样,获得相同尺寸的特征图。然后,用刚才获得的权重和上采样后的特征图乘累加,再通过一次标准化算子,最后的注意力图需要用最大选择策略,即不同尺度在各自分支获得的Features先在通道维度上拼接,再用最大值法获得最终的注意力图。以上就是多尺度融合网络的机制。
生成器的损失函数包含adversarial loss、content loss、attention loss三项,content loss让生成器生成和红外图像数据分布更接近的图像,因为红外图像对热量敏感,体现在像素幅度上;attention loss是由于引入了多尺度注意力机制。当判别器无法区分融合图像和源图像时,判别器的两个输入应该具有相同的注意区域。例如,最终的融合结果应该从红外图像中保留足够的典型信息,然后当判别器无法区分融合图像和红外图像时,融合结果和红外图像应该具有相同的注意力图。因此为了从源图像中保留更多注意力区域的信息,设计了融合图像与源图像之间的attention loss,对融合图像的注意力图与源图像的注意力图之间的差异进行惩罚(约束),具体的公式参考专栏3.10。
3.DRF
Disentangled Representation for Visible and Infrared Image Fusion (Information Fusion, 2021)
这篇文章的损失函数和之前的方法差异较大。本文将图像分解为场景特征图和属性向量,分别表示两个模态的共同信息和不同信息,个人认为这也是对互补信息的一种探讨。
大致思想:本文将Disentangled representation应用于可见光和红外图像融合。根据成像原理,将可见光和红外图像中的信息来源进行分解,即分别通过相应的编码器将图像分解为与场景模态和传感器模态(属性)相关的表示。这样,由属性(传感器模态)相关表示定义的唯一信息更接近于每种传感器单独捕获的信息。因此,可以缓解独特信息提取不当的问题。然后应用不同的策略来融合这些不同类型的表示。最后融合的表示被输入到预训练的生成器中以生成融合结果。
传统的图像分解方法会使用同种方法对图像进行分解,一般来说可能会造成关键信息丢失,也可能会生成冗余信息。一些方法针对不同的模态采取了不同的信息描述,例如对红外图像用像素幅度来描述,对可见光图像用梯度来描述,然而这种人工设计的信息分离方法也不能完整地描述图像信息。为了解决这个问题,应该尽可能地从源图像中的公共信息中分离出唯一信息。为此,可以从源图像的成像过程这个方向探讨信息的保留方式。无论源图像是从可见光传感器还是从红外传感器捕获的,它们都是从同一场景中拍摄的,其中包含大量(共同的)场景信息。不同之处在于这两种类型的传感器使用其特定的成像方式来捕获原始信息,具体方法是将源图像分解为两个部分:场景信息和传感器模态相关的信息。由于与传感器模态相关的信息反映了传感器或源图像的属性,我们将这类信息定义为唯一的属性表示;而来自场景的信息,即场景表示,是两者的共同信息。基于以上思考提出了新的融合模型:disentangled representation for visible and infrared image fusion (DRF) 。
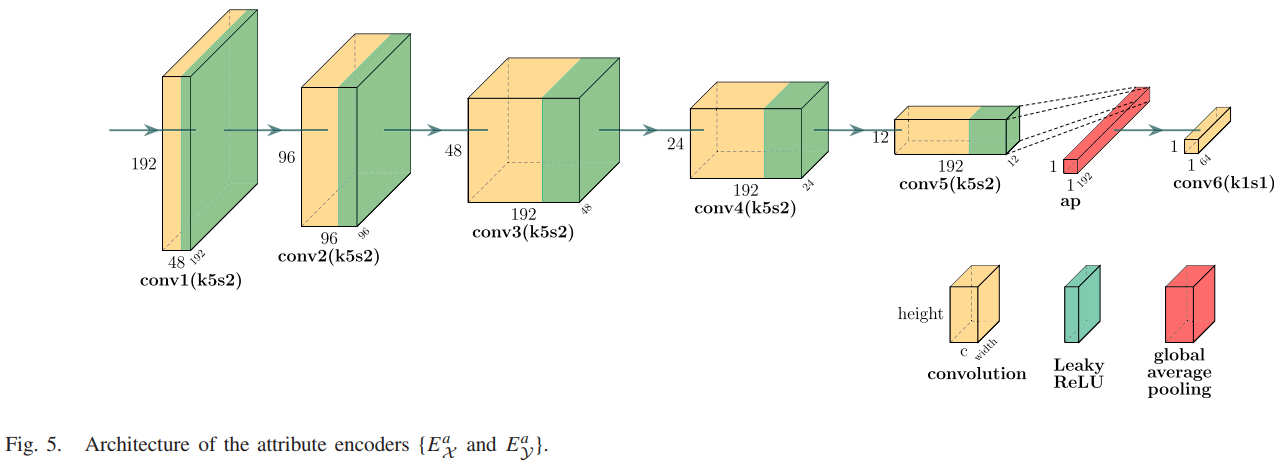
在DRF中,用disentangled representation来解构源图像中的场景和属性表示。场景信息通过一个场景编码器被作为公共信息来提取,属性表示通过一个属性编码器被作为唯一信息来提取,结构如下图所示。
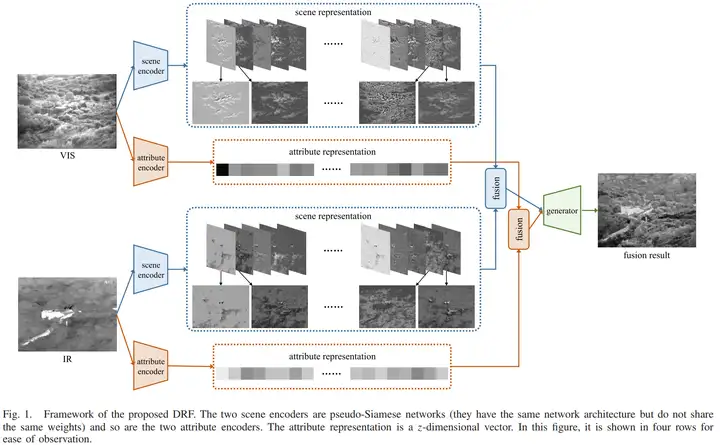

考虑到场景信息直接和空间、位置相关,所以场景表示就用特征图的方式来呈现(Fig 1的形式)。而属性是和传感器模态相关的,不必捕获场景信息,所以属性更适合通过一个向量来表示。
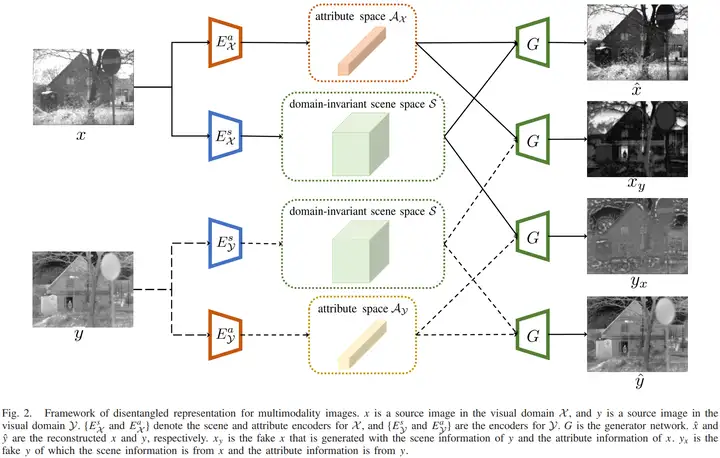
为了实现Disentangled representation,提出以下三个策略。首先,红外图像域X和可见光图像域Y的场景编码器最后一层参数共享,通过这样的方法就可以使两个域图像的场景特征嵌入到同一空间中了,但是共享高层权重的方式不能保证场景编码器对来自两个不同域的相同信息进行编码。所以第二个策略是对场景特征进行约束,让X和Y的场景编码器对来自两个域的相同场景特征进行编码。第三个策略,为了压缩属性空间中的场景信息,要对属性向量的分布进行约束,因此属性编码器不会对场景相关信息进行编码。
接下来,为了能让场景和属性两种信息表示源图像,那么通过场景S和属性A必须能够恢复源图像,因此加了一个生成器G来学习这种逆映射。考虑到Ax和Ay对生成器来说是不一致的,并考虑到后续的融合过程,{S,Sx}到X、{S,Ay}到Y的(逆)映射过程共享一个生成器,希望G能同时具有这两种映射的能力。
一方面,重建得到的x和y应该尽量和源图像x和y相似,这个容易理解。另一方面,S最好跨域X和Y捕获信息,而Ax和Ay应该捕获相应域的特定属性,而不携带域不变的场景相关线索。那么,假设X和Y是对同一场景的描述,那么\(s_x\)和\(s_y\)应该是相似的。相反地,给定不同的属性向量,生成器G生成的图像应该和提取属性向量那个模态的图像相同,而和没有提取属性向量那个模态的图像不同。举个例子,以\(s_x\)和\(a_y\)为条件,G生成的图像形式应该是这样的:\(y_x\)是一个由X场景信息和Y的属性信息生成、重建结果看起来像Y的图像,\(y_x\)和Y应该保持像素连续性。
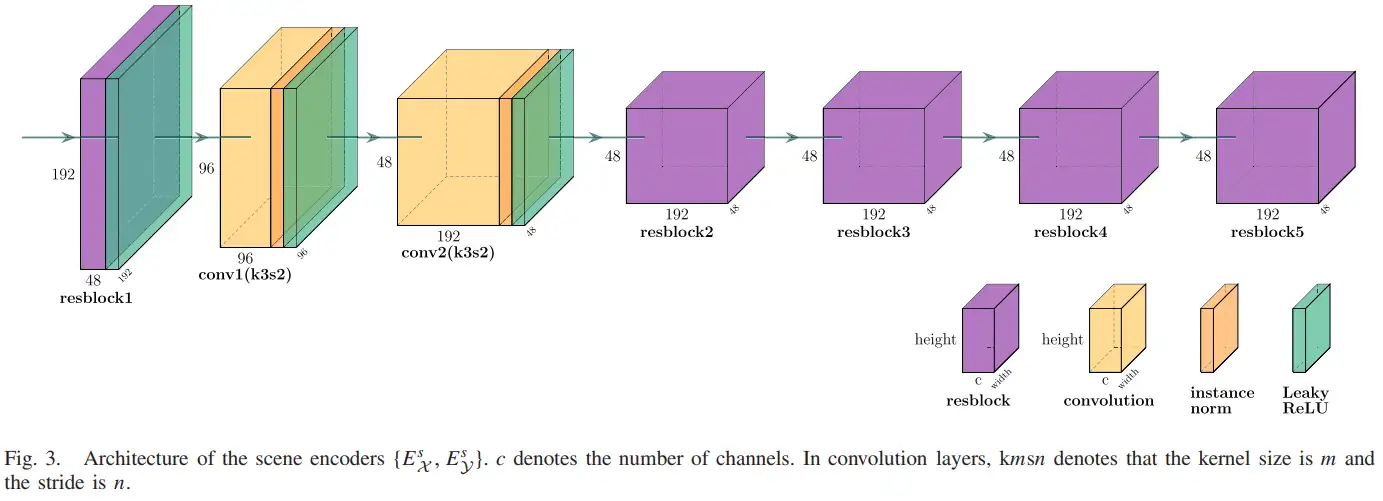
网络结构:场景编码器分为红外场景编码器和可见光场景编码器,结构如下图,一共包含七个层,5个残差模块和2个卷积层。
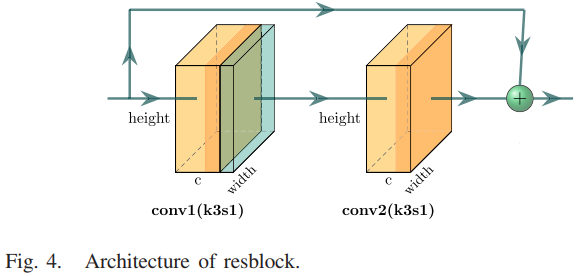
其中残差块的结构如下图所示:
属性编码器结构如下图,卷积层都是5×5的卷积核搭配长度为2的步长,然后在通道维度上进行全局平均池化,属性信息就被映射到向量形式了。
生成器结构:
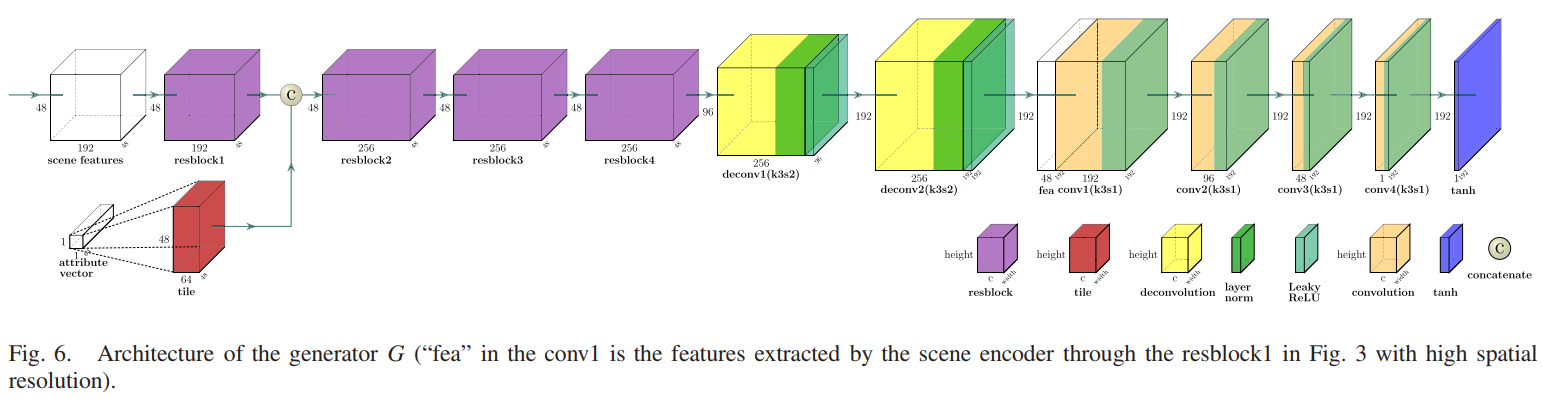
对场景特征,首先通过一个残差块处理,而对属性向量,会被平铺到和场景特征图一样的尺寸,这样就能和场景特征图在通道维度上进行拼接了。再经过几个残差块后用反卷积层对特征图进行上采样。场景特征图的空间分辨率降低到原始图像的四分之一,因此丢失了许多高质量的纹理细节,为了弥补损失,将场景编码器中第一个残差块的输出,和生成器中第二个反卷积层的输出进行拼接,送入后续的卷积层中。再经过多个卷积层,通道数量被削减到和输入图像通道数量一样,最后一个tanh后就是重建得到的图像。
融合模块,由于场景特征共享同一场景,因此用平均策略融合\(s_x\)和\(s_y\),属性特征\(a_x\)和\(a_y\)直接加权求和。以上两种特征图用一个预训练的生成器G来获得融合图像:\(f = G(s_f,a_f)\)
损失函数由以下几项构成:
(1)场景特征一致性损失Scene Feature Consistency Loss 给定描述同一场景的源图像x和y,它们的场景特征需要类似。因此该项损失用1-范数或者Frobenius-norm进行约束。但是本文发现L1-norm更合适,因为红外和可见光传感器的成像原理不同,这两种源图像中的场景信息不可能完全相同,但是整体而言场景信息不同的区域还是非常小的,大部分区域的场景信息能保持相同就可以了,那些小部分场景信息不同的区域实在不行就算了。换句话说,希望两个模态场景信息中的差异是稀疏的,因此相比较Frobenius-norm,L1-norm更合适。
(2)属性分布损失Attribute Distribution Loss 基于Disentangled representation的考虑,希望能在属性空间中尽量压缩场景信息,预计属性表示将与先验高斯分布一样接近。KL项会促进disentanglement,因此对x和y属性向量的分布施加约束,通过测量它们的分布和先验高斯分布之间的KL散度并对此进行约束。
(3)自重建损失Self-Reconstruction Loss 原始源图像将根据场景和与之分离的属性表示进行重建。也就是说,生成器G应该能够将场景特征和属性向量解码回原始源图像。因此,我们执行自重建损失以使重建的图像与原始图像达到高保真度:\(L_{reconstruction} = \Vert x - \hat {x} \Vert_1 + \Vert y - \hat {y} \Vert_1\)
(4)域转换损失Domain-Translation Loss
转换后的图像是根据一张源图像的场景特征和另一张源图像的属性向量生成的。

19-21年论文小结
总体来说自监督模型在损失函数方面,像素幅度的信息的计算使用的还是L2-norm/MSE较多,细节纹理信息的计算使用的是SSIM和梯度算子较多。2020年之前的很多模型为修改网络结构和损失函数的形式,早期的融合规则方面有使用attention形式的规则,但仍然是人工设计的融合规则,其中非学习方式产生的显著性图不能反映原图信息的有效性,还是应该用网络来学习融合规则。早期还有用预训练好的VGG进行特征提取,然后融合特征图的方法,但是提取到的特征不一定准确,毕竟不是专门通过多模态图像训练的网络。不过也逐渐有文章开始探讨什么是互补信息,以及如何在实际的融合过程中找出图像对中每个模态的互补信息(或者说一个区域中该模态有,而其他模态没有的信息)。
基于GAN的方法可以利用无监督对抗学习模型,充分利用源图像的信息。损失函数主要是设计content loss和adversarial loss。难点是生成器和判别器之间的平衡难以达到。对于图像融合的模型结构,综述Image fusion meets deep learning: A survey and perspective中认为当前用于图像融合的网络结构最有效的三种是残差连接、dense连接和双分支。提升深度学习模型的两种方式:1.设计高质量的指标用于无监督学习(高质量的评价指标不光可以用于损失函数,也对模型的真实效果评价有利);2.构建接近真实场景的数据用于有监督学习。
未来需要根据任务设计更具有针对性的网络,比如做任务驱动的模型,根据下游任务来决定融合的损失函数,例如SeAFusion,不然的话融合效果的评价还是比较主观的。
补充 4.TransMEF
A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning (AAAI, 2022)
目前用CNN做融合的模型很多都把CNN用在编码器上用于特征提取,但是CNN本身存在感受野小、不能提取长程信息的问题。而图像融合中,融合图像的质量不仅和感受野内的每个像素相关,也和图像整体的像素强度与纹理信息有关,所以同时对全局和局部信息建模是有必要的。所以本文针对多曝光图像融合提出了transMEF模型,这是一种基于transformer的自监督多任务学习模型,也采用编码器-解码器结构,在大规模自然图像数据集上进行自监督训练。融合过程中,首先使用编码器提取源图像的特征图,然后用解码器生成融合图像。
总结本文创新点:1.根据多曝光图像的特点提出三个自监督重建任务,基于多任务学习训练出了一个自编码器,所以模型不仅能在大规模自然图像上训练,也可以学习到多曝光图像的特点;2.为了克服CNN难以捕获长程信息的缺陷,提出了包含transformer结构的编码器结构,这样在特征提取过程中局部和全局信息都能捕获;3.在一个benchmark上和其他12种模型,依据11个指标进行了对比。
模型总体结构图: 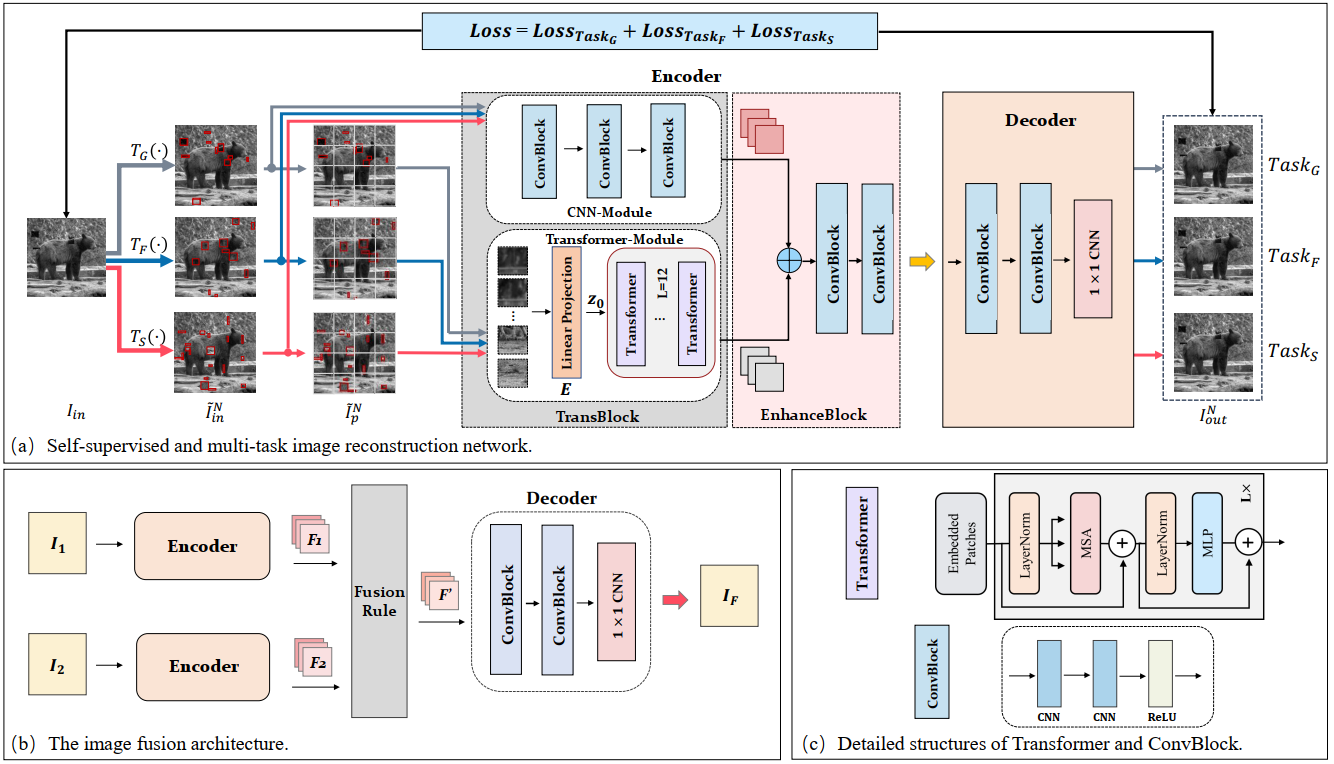
网络的训练和以前使用CNN的编码器-解码器融合网络类似,即直接将整体作为一个图像重建来训练自编码器。给定一个输入图像,通过三种不同的变换(Gamma-based transformation: TG(·), Fourier-based transformation: TF (·) and global region shuffling: TS(·))对源图像的多个区域产生失真,产生三种不同的失真图像,然后将这些失真图像送入编码器中。编码器包含一个特征提取模块(TransBlock)和一个特征增强模块(EnhanceBlock)。其中TransBlock包含CNN和transformer,CNN的输入直接将整图输入即可,而transformer则是将图像先分为多个patch,再送入transformer中训练。TransBlock的输出再送入EnhanceBlock对特征图进行聚合与增强,完成之后送入解码器中重建图像。上述三个任务使用多任务学习同时进行。自编码器训练好后,输入图像就能通过编码器得到特征图了,用上图b的方式对特征图进行融合。
基于transformer的编码器-解码器结构:前述所说第一阶段的重建训练首先要使用三种方式生成三种失真图像,具体做法是:在每种方式下,对一张输入图像随机产生10个子区域,每个子区域的宽和高是1到25之间的随机整数,然后每张图像在这10个子区域中进行变换,产生失真的子区域,替换源图像的该区域。而三种变换方式就对应TG(·)、TF (·) and TS(·),和结构图中的三种方式一一对应。然后把这些失真图像送入TransBlock进行特征提取即可。而EnhanceBlock则是将TransBlock输出特征图的全局和局部信息进行聚合,具体是先将CNN和transformer分别输出的特征图在通道维度进行拼接,然后再送入两个卷积块(ConvBlock)中,以此来强化特征。结构图c展示了Transformer和ConVBlock模块的具体组成,每个卷积块包含两个3×3、padding为1的卷积层,解码器中的卷积块也是如此。
TransBlock:该模块下的CNN部分比较简单,直接级联三个卷积块即可,输入就是完整的三类失真图像。而transformer部分则是先将三类失真图像分成多个P×P大小的patch序列,再用Linear projection获得embedding,将这些embedding送入L层的transformer,得到输出。Transformer的结构包含多头注意力MSA、LayerNorm、残差连接和MLP,其中MLP是两个使用RELU激活函数的线性层。
损失函数:损失函数用于多任务学习,针对三类失真图像同时训练三种图像重建任务,在上面的结构图a中最上方有Loss的公式,三项分别对应三类重建任务的损失。每一项任务的损失 \(Loss_{Task_i}\) 都不仅考虑像素级损失,还要考虑结构性损失和梯度信息。三项分别设计为:计算像素级损失的MSE、计算结构损失的SSIM和计算总变分损失的TV范数。
\[L_{MSE} = \Vert I_{out} - I_{in}\Vert_2\] \[L_{SSIM} = 1 - SSIM(I_{out},I_{in})\]
第三项的total variation项(TV损失)用来减少图像的虚假边缘和噪声等失真,同时能保留源图的边缘信息。计算公式如下:
\[R(p,q) = I_{out}(p,q) - I_{in}(p,q)\] \[L_{TV} = \sum\limits_{p,q} (\Vert R(p,q+1) - R(p,q) \Vert_2 + \Vert R(p+1,q) - R(p,q)\Vert_2)\]
从上式能看出R其实计算的是源图和重建图像之间的差分。
融合规则:直接将两个原始图像经过编码器得到的F1和F2平均即可。
三类图像重建任务:用于在训练编码器-解码器阶段,对原始输入图像进行变换,产生失真图像,该失真图像作为训练图像重建任务的输入图像。
1.首先是使用基于Gamma的变换方式来学习场景内容和亮度信息。过曝图像对于实际场景中较暗区域的细节信息保持的较好,欠曝图像则对实际场景中较亮区域的细节保持的较好,因此希望融合图像在能保持每个区域丰富细节的同时也能让图像的亮度较为统一。所以这里用Gamma变换对源图像的多个子区域进行亮度改变,使编码器能应对不同亮度条件下保持细节和结构信息的能力。
2.使用基于傅里叶变换的方式在频域学习细节和纹理信息。对一张图像进行离散傅里叶变换DFT后得到的频谱图中,振幅确定图像的强度信息,相位主要确定图像的高级语义,并包含有关图像内容和物体对象位置的信息。欠曝和过曝图像的直方图都不是很居中,所以希望网络能学习到合适的曝光度。而相位则较好地保持了物体的形状和内容信息,所以也需要网络能够捕获形状和内容信息。这一步具体做法是先把源图转换到频域,然后对子区域在频域上进行失真处理,针对振幅采用高斯模糊,针对相位对所有相位值执行np次随机交换,np是在1到5之间的随机正整数。
3.使用全局shuffle学习结构和语义信息。该方法来源于Kang等人的一篇论文内容,具体做法是:对于待失真处理的每个子区域,在图像中随机选一块和该子区域尺寸相同的子区域,然后将这两个区域调换位置,重复10次就完成了一张源图的全局shuffle失真变换处理。
彩色图像融合:首先将图像转换为YCbCr通道,Y通道的融合方式和上述方式保持一致,而Cb和Cr的融合使用传统的加权求和方式。
补充 5.VIF-Net
An Unsupervised Framework for Infrared and Visible Image Fusion (IEEE, 2020)
图像融合是信息融合的一种,本质就是增强技术,运用多传感器获得的不同数据来提高网络性能。相对于单传感器的数据局限于一种的特性,多传感器能同时利用多种数据的特性,在视频监控、卫星成像、军事上都有很好的发展前景。对于本文来说,可见图像提供了丰富的纹理细节和环境信息,而红外图像则受益于夜间可见性和对高动态区域的抑制。
图像融合最关键的技术是怎么样能融合(利用)多种数据的优势。往往引入的多种数据是双面性的,所以要抑制不同类型数据带来的干扰。
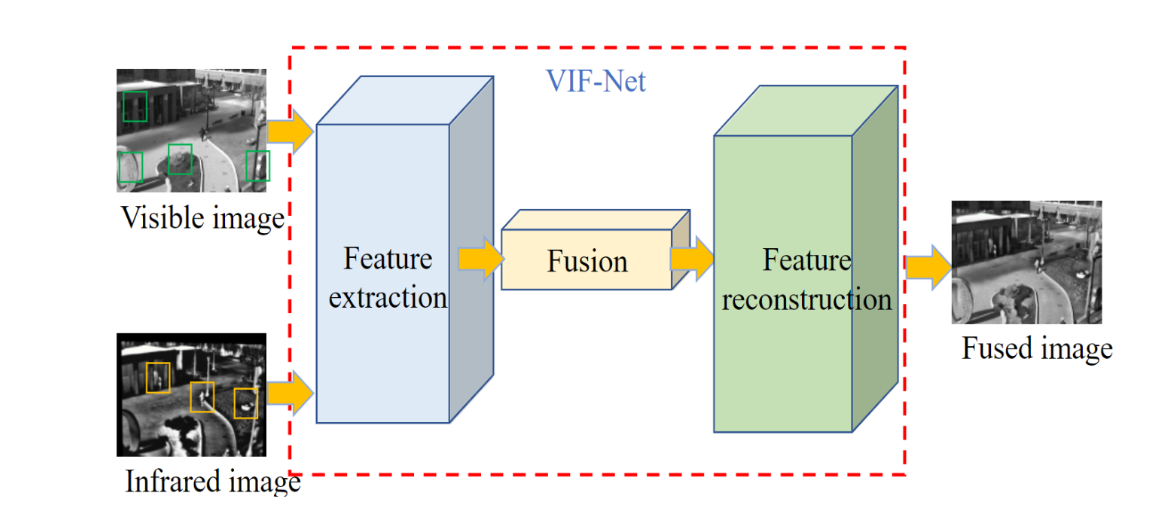
上图展示了图像融合的基本操作,将可见光和红外图像同时输入网络中,依次进行特征提取、特征融合、特征重建,最终生成融合图像。中间网络的部分就是作者提出的VIF-Net,全称为Visible and Infrared image Fusion Network,就是可见光和红外图像融合网络。
本文提出自适应端到端的无监督深度学习模型VIF-Net,比较新颖的地方是损失函数中使用像素强度来衡量每个源图像局部区域红外温度显著性,然后根据红外信息的显著性程度,决定保留相应模态下源图像局部区域的特征信息,也就是指导网络让融合图像的相应位置的局部区域特征更接近红外温度信息更显著的那张源图像。
模型结构如下:
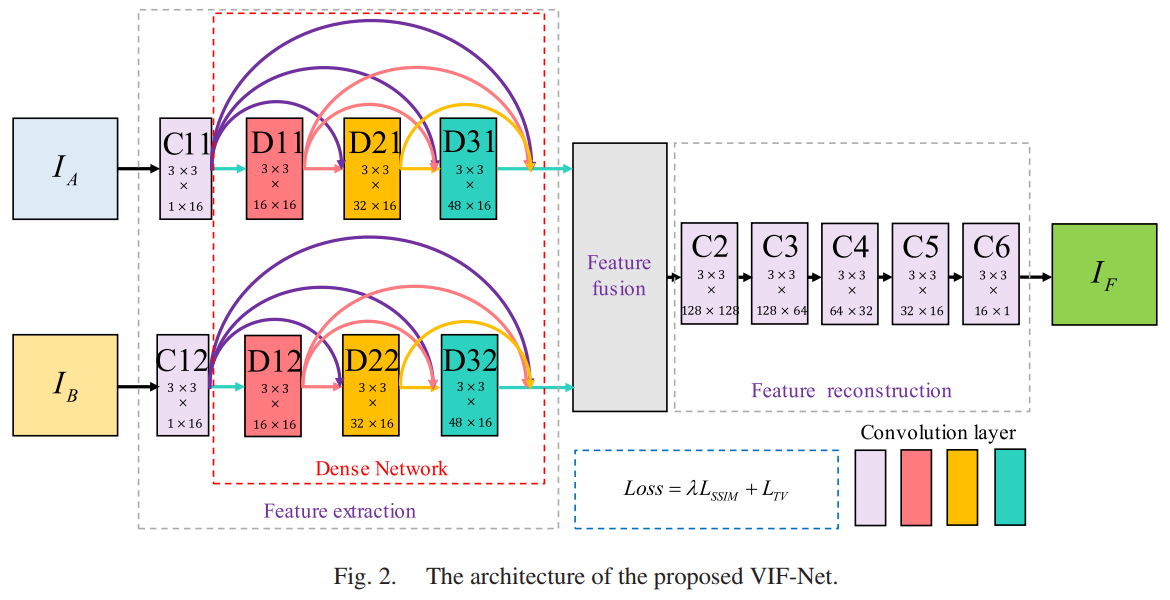
红外图像\(I_B\)和可见光图像\(I_A\)各占一个分支进行特征提取,并且两个支路的卷积层参数是共享的(权重相同以提取相同类型的模式或者说深度特征,同时又可以降低计算复杂度)。C11和C12提取底层特征,具体的卷积层设置情况如下表所示。
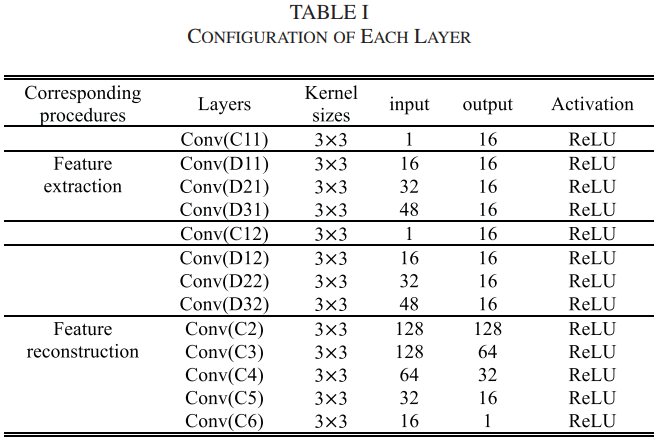
得到提取的特征图后,融合方法是直接将两个模态下的特征图在通道维度上拼接,然后将拼接好的特征图继续用卷积层C2~C6进行处理(重建),输出最终的融合图像。假设输入都是单通道的图像,经过前面的特征提取层,由于密集连接的作用,每一层的输出都会与后面所有层的输出直接相连(这里是通道叠加)。这样,可见光通道会输出 16+16+16+16=64 通道的特征图,两个网络通路会输出128通道的特征图,因此C2特征重建的输入是128个通道。
损失函数使用了Modified Structural Similarity(MSSIM)和Total Variation(TV-Norm),用这两项对网络进行无监督训练:
\[Loss = \lambda L_{SSIM} + L_{TV}\]
SSIM是一种衡量图像结构相似性的算法,结合了图像的亮度、对比度和结构三方面对图像质量进行测量。原本的SSIM公式为:
\[SSIM(X,Y) = \dfrac{(2\mu _X\mu _Y + C_1)(2\sigma _{XY} + C_2)}{(\mu _X^2 + \mu _Y^2 + C_1)(\sigma _X^2 + \sigma _Y^2 + C_2)}\]
本文模型想要设计一种专门处理红外与可见光融合的结构项损失,ImageNet中曾经指出:亮度在较低分辨率下,不能测量全局亮度一致性,因此局部patch中的亮度信息就不是很重要了,所以本文将SSIM中计算亮度的相似度项去掉了,新的SSIM损失项计算如下:
\[SSIM_M(X,Y|W) = \dfrac{(2\sigma _{XY} + C)}{(\sigma _X^2 + \sigma _Y^2 + C)}\]
这样就能分别计算融合图像与红外图像、可见光图像的结构相似度了。W代表一个滑动窗口,实际计算时本文通过11×11的滑窗遍历整幅图像就能得到计算结果了。
对于红外图像的温度显著性,温度越高的目标其像素值也会越大,所以一般用像素强度E(I|W)来衡量红外图像的温度信息。所以作者就产生了这样的想法:用每个滑窗内E(I|W)的大小来指导SSIM的计算。具体的做法是:对于两张源图像A和B,如果A一个滑窗内的像素强度值E(I|W)大于B中该位置对应滑窗内的像素强度值E(I|W),那么就会认为A在该局部区域内的红外温度信息比B的显著,所以就希望网络多保留一些A的特征信息,也让融合图像的该局部区域和A的该区域更相似。最后提出了下面这种计算损失函数的方式(式中的E(I|W)实际上是计算的是该滑窗内所有像素点值的和,而非MSE或者L2范数这种方式)。

除了SSIM项,损失函数还有一个总变分项来保留源图像的边缘信息,去除噪声。TV全称是Total Variation,译为总体变化,是一种衡量图片噪声的指标。
理解TV的原理可以参考“专业笔记”栏目中距离度量-范数篇附的链接,传统的TV计算公式为:
\[R_{V^{\beta}(x)} = \sum\limits_{i,j} \Big((x_{i,j+1} - x_{i,j})^2 + (x_{i+1,j} - x_{i,j})^2 \Big)^{\frac{\beta}{2}}\]
其中,\(x_{i,j}\)代表一个像素,将其与水平方向+1的像素做差的平方,并且与垂直方向+1的像素做差的平方,两者之和开\(\frac{\beta}{2}\)的次方,如此遍历除最后一行和最后一列之外的所有像素点,就可以计算出TV。如果有噪声,噪声点与其他像素之间的变化会很大,TV会明显变大。如果TV很小,说明相近的像素差值较小甚至为0,图像会比较模糊。
作者运用下列公式计算\(L_{TV}\):
\[R(i,j) = I_{A}(i,j) - I_{F}(i,j)\] \[L_{TV} = \sum\limits_{i,j} (\Vert R(i,j+1) - R(i,j) \Vert_2 + \Vert R(i+1,j) - R(i,j)\Vert_2)\]
上式相当于对可见光图像与融合图像做差分,\(\beta\)取2。
总的损失函数是:\(Loss = \lambda L_{SSIM} + L_{TV}\),而这两项的实际差值较大,在100至1000之间。如果SSIM项的值较低,会造成融合图像对比度不高,质量低的结果。TV项的结果如果较低,融合结果会丢失更多可见光图像的细节。所以这里引入\(\lambda\)来平衡两项。