文献整理 · 海纳百川篇
Last updated on June 4, 2024 pm
L-PUIF
A Lightweight Pixel-Level Unified Image Fusion Network, 2023(IEEE)
Motivation
传统的图像融合虽然computational cost很低,但是随着GPU的发展,高计算能力平台使其这一优势变得越来越平常。而且传统的像素级融合在提取特征和计算融合策略时高度依赖expert knowledge,且需要人工设计融合规则,这会限制模型的泛化能力,同时这些方法普遍需要根据融合的类型调整参数,这一过程比较复杂。因此深度学习技术成为unified image fusion的主流。
The feature extraction methods of these traditional methods are too single and difficult to adapt to different types of fusion tasks, which greatly limits the fusion performance.
但是一些deep learning networks的网络性能仍然需要prior knowledge来支撑,比如需要ground truth去指导融合的迭代过程,或者是使用fixed-parameter feature extraction network分析源图像的信息。此外,还有一些深度学习网络使用大量的参数来达到更高的融合质量。现有的一些方法也没有过多关注不同类型源图像之间的data specificity,这将限制融合网络的性能。
Hence, how to combine the specificity of source images is the key to image fusion.The existing methods are only aimed at the fusion effect or the robustness of the model, ignoring the requirement of real-time needs. In fact, the FPS of the existing network is far lower than the standard of 30 when facing high-resolution datasets.
为了克服上述问题或缺陷,作者设计了一个轻量化的像素级统一(联合)图像融合网络:L-PUIF,适用于三种融合场景:多模态、多聚焦和多曝光。
Introduction
作者发现广泛使用高维多尺度特征提取模式不适合构建轻型网络,因为高维、多尺度特征缺少局部细节信息,会增加计算成本和图像重建的复杂性。
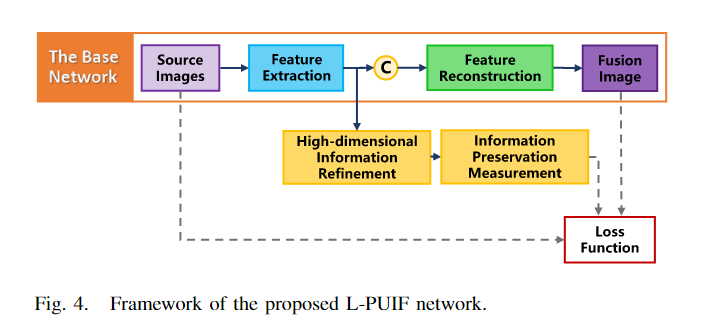
基于此,作者提出一个base network,由4个不同的卷积层组成,用于特征提取与重建;一个high-dimensional refinement(精炼、细化) process,增强特征提取的信息挖掘(information mining)能力。
提取的高维特征通过应用于损失函数的information preservation measurement生成权重,引导网络对structure, intensity, and other info from the source images进行合理利用。
这样,网络就可以实现无监督图像融合过程,减少模型参数,实现统一、准确、高效率的图像融合。
作者的contributions总结如下:
A lightweight network named L-PUIF is proposed, which avoids the redundant structural and can be adapted to different pixel-level image fusions with one training model.
A new measurement method of information preservation degree for image fusion has been proposed, which can adaptively enhance the gradient and intensity info extraction ability of the network.
Method
作者提出的L-PUIF方法可以消除先验信息和人工操作的限制,轻量化网络模型,具有良好的实时性、较高的融合效率和较好的可视化融合结果。
特征提取在图像融合中是相当重要的环节。作者将特征提取分为两类主要的模式:一种是高维度特征提取,如FusionGAN,另一种是多尺度特征提取,如RFN-Nest。实验表明,small-scale features和high-dimensional features包含的信息几乎都是全局信息和语义信息,而局部细节和强度信息丢失。这两种模式的网络结构很大,不利于图像重建的快速实现。然而,texture, intensity, and other info可以从尺度不变特性和低维特征中获得,对图像融合和重建起重要作用。即:这两种patterns在构建轻量级融合网络中不是必需的。
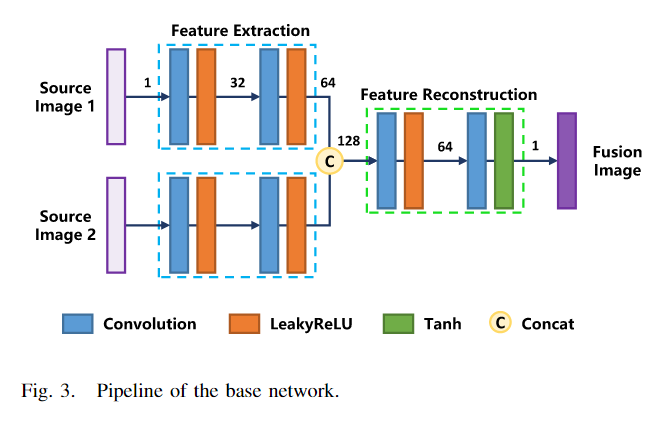
1.Base Network
该网络主要由特征提取和特征重构模块两部分组成。首先,我们使用具有相同权重的特征提取模块来处理两个不同的输入。这样,网络的特征提取参数可以通过两个不同的源进行优化,可以减少网络模型的大小。特征提取模块有两层组合,每一层由卷积层和激活函数组成。
我们没有使用手动融合策略,例如加法或L1范数,而是选择拼接不同源图像生成的特征,并将它们放入特征重建模块中。特征重构模块的结构与特征提取模块相同。具体来说,它完全由3*3卷积构建,特征重建模块中最后一层的激活函数是tanh函数,而其余激活函数是Leaky ReLU。最后,根据融合图像和源图像计算损失函数。
2.High-Dimensional Information Refinement
基础网络仅将来自不同来源的图像融合到一张图像中,但由于网络体积的限制,网络的特征提取能力并不突出。因此,需要通过其他方法提高基础网络的特征提取能力。我们针对基础网络提出了一种高维信息处理方法,增强了对所需信息的利用,优化了整个网络融合过程。
具体思想是:高维特征由基础网络的特征提取模块生成,该模块包含大量源信息。我们通过high-dimensional information refinement过程重新提取高维特征,并在随后的步骤中将提取的信息注入到损失函数中。这样,特征提取模块可以通过特征重构过程和高维特征提取过程进行优化。这种优化方法还增强了网络中前后特征的交互性。
我们使用1*1的卷积和tanh激活函数来进行高维特征提取,输入是基础网络的特征提取结果。将生成的张量提供给information preservation measurement过程进行进一步处理,网络架构如下图所示。
3.Information Preservation Measurement
在基础网络中,来自不同源图像的信息对融合结果的影响是相等的,无法处理数据特异性和其他属性。因此,有必要为损失函数获得合理的权重来定义不同源图像的影响。U2Fusion为这个问题提供了初步解决方案。U2Fusion使用具有确定参数的VGG-16网络提取源图像不同维度和尺度的特征,然后计算这些特征的梯度,并为损失函数生成两个不同的权重。这样就考虑了不同的源图像对融合图像的影响。
然而,这些信息测量方法不是逐个像素地实现的,而且需要一些先验信息来提高测量精度。因此,我们提出了一种更好的方法来评估融合信息。首先,我们认为这个权重可以从像素级进行确定,其可以灵活地反映图像中不同区域的差异。其次,不需要预定义权重,而是通过从源图像训练网络来获得(学习)权重。基于上述考虑,我们提出了一种信息保存测量方法,该方法使用两个high-dimensional information refinement过程生成的张量作为输入,评估梯度和强度信息。梯度和强度是融合中最关键的两种信息类型,它们可以同时反映图像的局部和全局信息。这两种信息为损失函数生成两组不同的权重W1, W2; W3, W4。这种像素级融合权重可以根据源图像的特征自适应调整,使融合结果更适合不同类型的融合。同时,这些权重有利于信息的存储和计算。
梯度信息权重\(W_1\)和\(W_2\)计算方式如下:
\[W_1 = \varepsilon (\vert F_{grad}(\Phi _1)\vert - \vert F_{grad}(\Phi _2)\vert)\] \[W_2 = 1 - W_1\]
\(\varepsilon ()\)表示阶跃函数,\(\Phi _1\)和\(\Phi _2\)表示不同中间信息层生成的特征。这样,我们就得到了融合图像中每个元素与源图像之间独特的对应关系。
为了进一步处理不同源图像强度的不均匀,我们减去同源元素的平均值,以减少非同源元素之间的差异。然后,使用sqrt函数扩大元素值之间的差异。因此,非同源元素被调节为平均值以促进元素强度的比较,可以表达为:
\[b_1 = sqrt(sigmoid(\Phi_1 - F_{mean}(\Phi_1)))\] \[b_2 = sqrt(sigmoid(\Phi_2 - F_{mean}(\Phi_2)))\]
\(F_{mean}(\Phi)\)表示元素的总和除以元素个数。为了获得\(b_1\)和\(b_2\)之间的相关性,将它们归一化为\(c_1\)和\(c_2\):
\[[c_1, c_2] = [\dfrac{b_1}{b_1+b_2}, \dfrac{b_2}{b_1+b_2}]\]
使用sigmoid函数对强度信息权重\(W_3\)和\(W_4\)归一化:
\[W_3 = sigmoid(c_1 - F_{mean}(c_1))\] \[W_4 = sigmoid(c_2 - F_{mean}(c_2))\]
\(W_1, W_2, W_3, W_4\)可以作为融合图像各个像素(元素)纹理和强度的约束信息,还可以帮助网络控制不同源图像的信息保存。这是L-PUIF的关键之处。
4.Loss Function
损失函数在图像融合中起着重要作用,它决定了不同源图像之间的信息相关性程度。更具体地说,源图像不同区域的信息量有很大的差异。在像素级图像融合中,应根据这些差异确定不同信息的使用。因此,我们使用损失函数来限制各种类型的信息之间的比例关系。
损失函数主要包括两部分:梯度损失\(L_{grad}\)和强度损失\(L_{int}\),系数\(\lambda\)权衡二者的比重:
\[L_{L-PUIF} = \lambda _1 L_{grad} + \lambda _2 L_{int}\]
\(L_{L-PUIF}\)计算融合图像与源图像之间的相似性(差异)。\(\lambda_1\) = 1、\(\lambda_2\) = 0.4。\(W_1\)和\(W_2\)用于梯度损失中,用来衡量不同源图像的影响。结构相似度指数测度(SSIM)和均方误差(MSE)用于计算图像的结构相似度和细节相似度。因此,梯度信息可用于保留融合图像中的局部纹理信息:
\[L_{grad1} = 2 - SSIM_{(W_1 \odot I_1,\ W_1 \odot I_f)} - SSIM_{(W_2 \odot I_2,\ W_2 \odot I_f)}\] \[L_{grad2} = MSE_{(W_1 \odot I_1,\ W_1 \odot I_f)} + MSE_{(W_2 \odot I_2,\ W_2 \odot I_f)}\]
上式中\(I_1\)和\(I_2\)代表源图像,\(I_f\)代表融合图像,\(\odot\)代表multiplication,即张量之间对应元素相乘。
\[L_{grad} = L_{grad1} + \alpha L_{grad2}\]
\(\alpha\)用来平衡两个损失,文中取20来确保可以平衡图像信息的内容。
与梯度损失的信息约束类似,\(W_3\)和\(W_4\)用于梯度损失中,使用MSE计算融合图像和源图像之间的强度相似度:
\[L_{int} = MSE_{(W_3 \odot I_1, \ W_3 \odot I_f)} + MSE_{(W_4 \odot I_2,\ W_4 \odot I_f)}\]
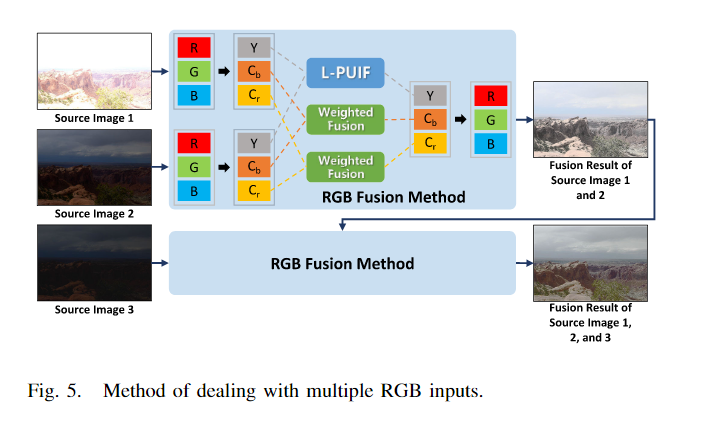
5.Multiple RGB Inputs
对于多通道彩色图像输入,将其转换至YCbCr颜色空间中,对Y通道进行L-PUIF融合,对Cb和Cr通道进行加权融合。融合完成后,将融合图像转为RGB图像即可。具体过程见下图所示。
Experiment
The parameter of our network is optimized by RMSPropOptimizer with a learning rate of 1e-4.
The batch size is set to 32.实验证明,L-PUIF在多模态(红外可见光)、多曝光、多聚焦三类图像融合任务中都有比较好的效果。
Limitation: 作者只选择了两类源图像中包含的两种主要信息:强度(显著信息)Intensity和梯度(纹理细节)Texture,没有考虑所有有助于提升融合性能的info。
PS (PostScript, 附言)
对应元素相乘: a*b | torch.mul(a,b) | np.multiply(a,b)
对应元素乘积,又叫哈达玛积:Hadamard product
矩阵乘法: a@b | torch.mm(a,b) | np.matmul(a,b) | np.dot(a,b)CDDFuse
Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion, 2023(CVPR)
Motivation
当前已存在的基于自编码器(Auto-Encoder)多模态方法有以下三个主要缺点:
第一,CNN的内部工作机制难以控制、难以解释,导致跨模态特征提取不够充分(个人理解:可能是因为无法解析内部具体的工作机理从而难以针对具体状态进行分析和处理)。
First, the internal working mechanism of CNNs is difficult to control and interpret, causing insufficient extraction of cross-modality features.
第二,与上下文无关的CNN只能在相对较小的感受野里提取局部信息,很难提取全局信息来生成高质量的融合图像。
Second, the context-independent CNN only extracts local information in a relatively small receptive field, which can hardly extract global information for generating high-quality fused images. Thus, it is still unclear whether the inductive biases of CNN are capable enough to extract features for all modalities.
第三,融合网络的前向传播经常导致高频信息的丢失。
Third, the forward propagation of fusion networks often causes the loss of high-frequency information.
Introduction
首先,我们在提取的特征中加入相关限制,从而提高特征提取的可控性和可解释性。本文假定:在Multi-Modality Image Fusion(MMIF)任务中,两种模态(红外、可见光)的输入特征在低频相关,表示模态共享信息;而高频特征不相关,表示各自模态的独有特征。因此,我们的目标是通过分别增加低频特征之间的相关性和减少高频特征之间的相关性来促进模态特定特征和模态共享特征的提取。
Our assumption is that, in the MMIF task, the input features of the two modalities are correlated at low frequencies, representing the modality-shared information, while the high-frequency feature is irrelevant and represents the unique characteristics of the respective modalities.
第二,我们结合CNN在局部上下文提取和计算效率方面的优势,以及Transformer \(^{[1][2]}\) 在全局关注(特征提取)方面的优势,完成MMIF任务。
We propose integrating the advantages of local context extraction and computational efficiency in CNN and the advantages of global attention and long-range dependency modeling in Transformer to complete the MMIF task.
第三,为了解决高频特征的丢失问题,我们采用倒置的神经网络INN(Invertible Neural Networks)构建块,通过输入和输出特征相互生成来保留高频特征。
INN was proposed with invertibility by design, which prevents information loss through the mutual generation of input and output features and aligns with our goal of preserving high-frequency features in the fused images.
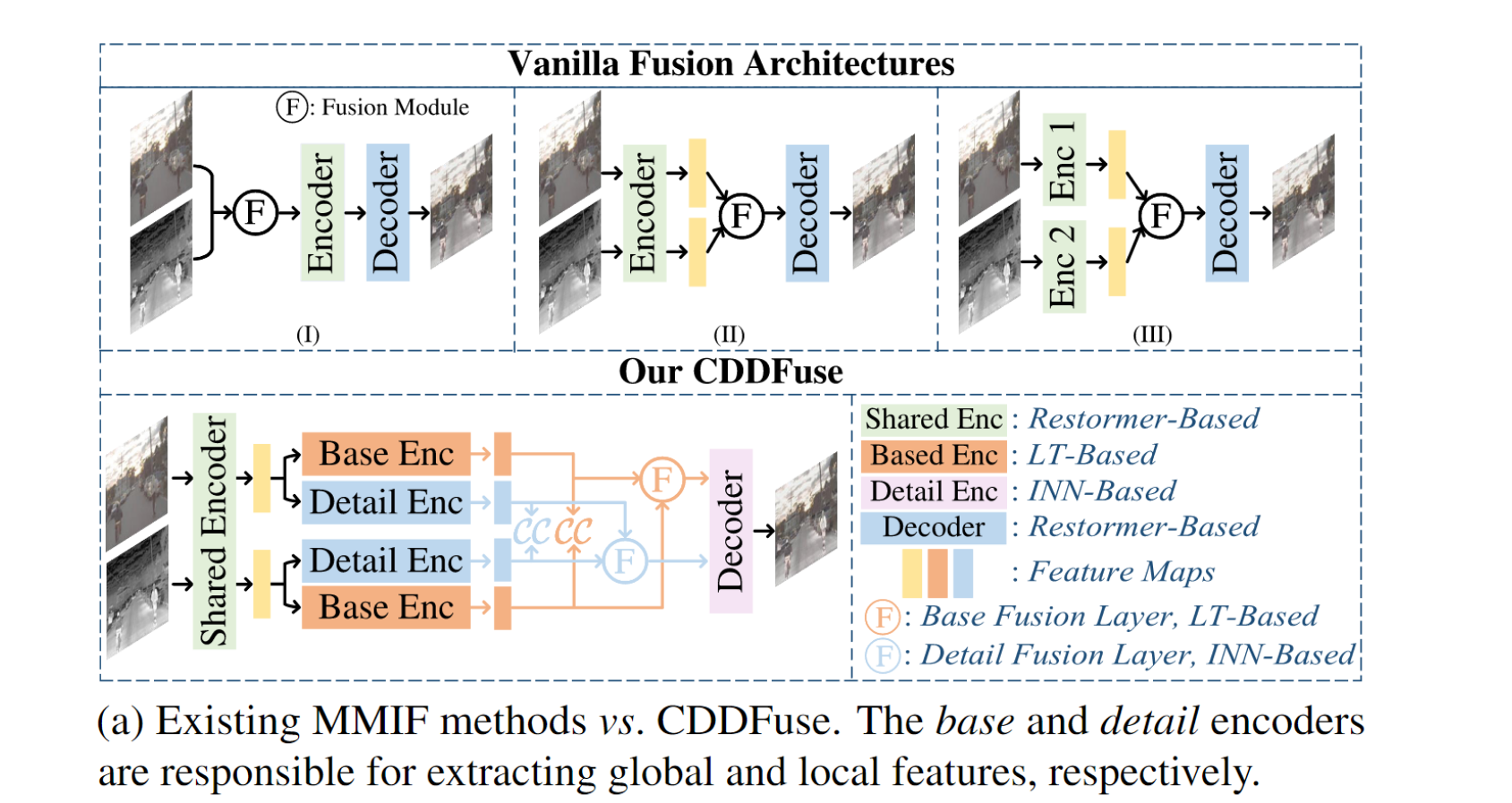
为此,我们提出了CDDFuse模型,模态特定和模态共享特征的提取由双分支编码器实现,融合图像重建由解码器实现。CDDFuse模型中包括以下几个重要模块:Lite Transformer \(^{[3]}\)、Restormer blocks \(^{[4]}\)、INNs \(^{[5]}\)。
To this end, we proposed the Correlation-Driven feature Decomposition Fusion (CDDFuse) model, where modality-specific and modality-shared feature extractions are realized by a dual-branch encoder, with the fused image reconstructed by the decoder.
Method
CDDFuse详细的工作流程如下图所示:
CDDFuse包括四个模块:双分支编码器(提取和分解特征)、解码器(重建原始图像和生成融合图像)、基础融合层(融合低频特征)、细节融合层(融合高频特征)。
Our CDDFuse contains four modules, i.e., a dual-branch encoder for feature extraction and decomposition, a decoder for reconstructing original images (in training stage I) or generating fusion images (in training stage II), and the base/detail fusion layer to fuse the different frequency features, respectively.
Encoder
编码器有三个components:the Restormer block -based share feature encoder (SFE)、the Lite Transformer(LT) block -based base transformer encoder (BTE)、the Invertible Neural networks(INN) block -based detail CNN encoder (DCE),分别用S(·)、B(·)、D(·)表示。
SFE用来从红外、可见光图像 {I,V} 中提取浅层共享特征:{\(\Phi _I^S\),\(\Phi _V^S\)},即:\(\Phi _I^S = S(I)\),\(\Phi _V^S = S(V)\)。在SFE中使用Restormer是因为其可以通过跨特征维度应用自注意力从高分辨率输入图像中提取全局特征。
BTE用来从共享特征中提取低频基本特征:\(\Phi _I^B = B(\Phi _I^S)\),\(\Phi _V^B = B(\Phi _V^S)\)。为了提取长距离依赖特征,并平衡性能与计算效率,在BTE中使用了带空间自注意力的轻量化(Lite)Transformer。
DCE与BTE相反,从共享特征中提取高频细节信息:\(\Phi _I^D = D(\Phi _I^S)\),\(\Phi _V^D = D(\Phi _V^S)\)。利用CNN强大的特征提取能力尽可能多的保留边缘、纹理等细节信息。INN模块通过输入和输出特征相互生成,使得输入信息能尽可能多的被保存下来。因此,它可以被看作是一个无损特征提取模块。
DCE中的INN模块比较复杂,计算公式请参考论文原文,计算细节可以看Figure 2(b),其中\(\Phi _{I,k}^{S}[1:c]\)表示第k个可逆层输入特征的第c个通道的第一个元素,\(I_i \ (i=1 2 3)\)是任意的映射函数。最终,\(\Phi _I^D = \Phi _{I,k}^{S}\),\(\Phi _V^D = \Phi _{V,k}^{S}\)。
Fusion layer
考虑到inductive bias for base/detail feature fusion应该与编码器中的base/detail feature extraction相似,我们对基础融合层和细节融合层采用LT和INN块。
\[\Phi ^B = F_B(\Phi _I^B,\Phi _V^B), ~~~~ \Phi ^D = F_D(\Phi _I^D,\Phi _V^D)\]
其中,\(F_B\)和\(F_D\)分别代表基础融合层和细节融合层。
Decoder
Decoder表示为DC(·),输入是已分解的在通道维度拼接后的特征,输出是(重建的)原始图像(训练阶段1)或者融合图像(训练阶段2),公式如下。
Stage 1: \(~~~ \widehat{I} = DC(\Phi _I^B,\Phi _I^D), ~~~ \widehat{V} = DC(\Phi _V^B,\Phi _V^D)\)
Stage 2: \(~~~ F = DC(\Phi ^B,\Phi ^D)\)
由于输入涉及跨模态和多频特征,我们保持解码器的结构与SFE一致,即使用Restormer block作为解码器的基本单元。
Two-stage training
这一部分相当于对上述内容的总结,这里直接引用论文原文的内容:
Training stage I: In the training stage I, the paired infrared and visible images \({I,V}\) are input into the SFE to extracts shallow features \({\Phi ^S_I,\Phi ^S_V}\). Then the LT block-based BTE and the INN-based DCE are employed to extract lowfrequency base feature \({\Phi ^B_I,\Phi ^B_V}\) and high-frequency detail feature \({\Phi ^D_I,\Phi ^D_V}\) for the two different modalities, respectively. After that, the base and detail features of infrared \({\Phi ^B_I,\Phi ^D_I}\) (or visible \({\Phi ^B_V,\Phi ^D_V}\)) images are concatenated and input into the decoder to reconstruct the original infrared image \(\widehat{I}\) (or visible image \(\widehat{V}\)).
Training stage II: In the training stage II, the paired infrared and visible images \({I,V}\) are input into a nearly well-trained Encoder to obtain the decomposition features. Then the decomposed base features \({\Phi ^B_I,\Phi ^B_V}\) and detail features \({\Phi ^D_I,\Phi ^D_V}\) are input into the fusion layer \(F_B\) and \(F_D\), respectively. At last, the fused features \({\Phi ^B,\Phi ^D}\) are input into the decoder to obtain the fused image \(F\).
Training loss
In training stage I, the total loss \(L_{total}^{I}\) is:
\[L_{total}^{I} = L_{ir} + \alpha _1 L_{vis} + \alpha _2 L_{decomp}\]
where \(L_{ir}\) and \(L_{vis}\) are the reconstruction losses for infrared and visible images, \(L_{decomp}\) is the feature decomposition loss, and \(\alpha _1\) as well as \(\alpha _2\) are the tuning papameters. The reconstruction losses mainly ensure that the information contained in the images is not lost during the encoding and decoding process, i.e.
\[L_{ir} = L_{int}^{I}(I,\widehat{I}) + \mu L_{SSIM}(I,\widehat{I})\]
where \(L_{int}^{I} = \Vert I-\widehat{I} \Vert _2^2\) and \(L_{SSIM}(I,\widehat{I}) = 1-SSIM(I,\widehat{I})\). \(L_{vis}\) can be obtained in the same way.
\[L_{decomp} = \dfrac{(L_{CC}^{D})^2}{L_{CC}^{B}} = \dfrac{(CC(\Phi ^D_I,\Phi ^D_V))^2}{CC(\Phi ^B_I,\Phi ^B_V)+\epsilon}\]
where CC(·) is the correlation coefficient operator(相关系数算子), and \(\epsilon\) here is set to 1.01 to ensure this term always being positive.
根据作者MMIF的假设,分解的特征\({\Phi ^B_I,\Phi ^B_V}\)包含更多的模态共享特征,如背景(background)和大范围环境(large-scale environment),因此它们通常是高度相关的。而\({\Phi ^D_I,\Phi ^D_V}\)表示可见光图像中的纹理细节信息和红外图像中的热辐射以及清晰的边缘信息,是特定模态的,相关性较低。按照经验,\(L_{decomp}\)这个损失项会随着梯度下降算法逐渐变小(趋于0)。
Evaluation
这篇文章的对比实验和消融实验做的很充分,评估指标很全面,值得推敲。本文提出了可见光-红外图像融合(VIF)领域中目前存在的三个问题,然后分别给出自己的解决方法,条理清晰。利用Restormer、Lite Transformer和Invertible neural network block,对modality-specific和modality-shared特征进行更有效的提取,并且采用correlation-driven decomposition loss对模型进行优化,我个人感觉都是很不错的创新。
[1] Transformer, firstly proposed by Vaswani et al. for natural language processing (NLP). Title: Attention Is All You Need (2017).
[2] ViT, proposed by Dosovitskiy et al. for computer vision. Title: An Image is Worth 16X16 Words: Transformers for Image Recognition at Scale (2021).
[3] Considering the large computational overhead of spatial self-attention, Wu et al. proposed a lightweight LT structure for mobile NLP tasks. Title: Lite Transformer with Long-Short Range Attention (2020).
[4] Restormer improves transformer block by the gated-Dconv network and multi-Dconv head attention transposed modules, which facilitate multi-scale local-global representation learning on high-resolution images. Title: Restormer: Efficient Transformer for High-Resolution Image Restoration (2022).
[5] The invertible neural network is an important module of the Normalized Flow model, a popular kind of generative model. It was first proposed by NICE, and later the additive coupling layer in NICE was replaced by the coupling layers in RealNVP. Subsequently, 1×1 invertible convolution was used in Glow, which can generate realistic high-resolution images. Relevant: NICE: Non-linear Independent Components Estimation (2014), Density estimation using Real NVP (2016), Glow: Generative Flow with Invertible 1×1 Convolutions (2018), Analyzing Inverse Problems with Invertible Neural Networks (2018).
引申
通用图像融合评估指标归纳:
- 基于图像特征的指标:平均梯度(AG)、空间频率(SF)、标准差(SD、STD)
- 基于相关的指标:相关系数(CC)、非线性相关系数(NCC)、差异相关性总和(SCD)
- 基于图像结构的指标:结构相似性度量(SSIM)、多尺度结构相似性度量(MS-SSIM)
- 基于信息熵的指标:信息熵(EN)、互信息(MI)、特征互信息(FMI)、标准化互信息(NMI)、峰值信噪比(PSNR)、关于边缘信息的指标(\(Q^{AB/F}\))、关于伪影的指标(\(N^{AB/F}\))
- 基于人类感知的指标:视觉保真度(VIF、VIFF)、人类视觉感知的度量(\(Q_{CB}\))
选取准则:尽量覆盖以上5大类评估指标,同时尽量避免使用太多表征相同特性的指标,比如AG和SF。
部分术语解释(公式自己查):
- AG(Average Gradient),用于衡量融合图像的清晰程度,平均梯度越大,图像越清晰
- SF(Spatial Frequency),反映图像灰度的变化率,空间频率越大,图像越清晰
- SD(Standard Deviation),是度量图像信息丰富程度的客观评价指标,标准差越大,图像灰度级分布越分散,携带信息量越多,质量越高
- CC(Correlation Coefficient),衡量两个变量之间的线性关系的强度和方向,如皮尔逊相关系数,取值范围是[-1,1],取值:1说明完全正相关,-1说明完全负相关,0说明无线性相关性
- NCC,衡量两个变量之间的非线性关系,如斯皮尔曼等级相关系数,取值范围是[-1,1],取值:1说明完全正相关,-1说明完全负相关,0说明无相关性
- SSIM,结构相似性度量,取值范围是[-1,1],该值越接近1,说明两幅图像越相似
- MS-SSIM,多层级SSIM,能更好地与人眼视觉系统的感知相一致,在一定尺度下,评价效果优于SSIM
- EN(Entropy),度量图像包含信息量的多少,信息熵越高,表示融合图像信息量越丰富,质量越好
- MI(Mutual Information),度量两幅图像之间的相似程度,即融合图像获取了源图像的多少信息,互信息越大,说明融合图像保留更多的源图像信息,质量越好
- FMI,特征互信息,由Mohammad在2011年发表的论文中提出,是基于互信息的图像融合质量评价指标,该值越大,表示融合图像质量越好
- NMI(Normalized mutual information),是度量图片相似度的一种方式,NMI值越大,表示融合图像保留了更多源图像的信息,融合效果越好
- PSNR,衡量信号的质量,一般超过50dB就说明信号质量已经非常好了
- \(Q^{AB/F}\),是论文中提出的方法,比较新,值越高,表示融合图像质量越好
- VIF(Visual Information Fidelity (for fusion)),是论文中提出的方法,取值通常在0-1之间,基于人眼感知系统,VIF的值越大,表示融合图像的质量越高