文献整理 · 旁搜博采篇
Last updated on May 12, 2024 pm
STFuse
STFuse: Infrared and Visible Image Fusion via Semisupervised Transfer Learning, 2023(IEEE)
Abstract
作者提出了一种基于半监督迁移学习的 IVIF(infrared and visible image fusion)方法,称为 STFuse,其目的是将知识从信息丰富的源域转移到目标域,从而突破标注信息(ground truth)或先验信息(prior knowledge)缺乏的限制。方法的关键是借用多焦点图像融合 MFIF(multi-focus image fusion)任务的监督知识,并使用引导损失(guidance loss)过滤掉特定任务的属性知识(MFIF相关的),这激发了其在 IVIF 任务中的跨任务使用。使用这种跨任务知识有效地缓解了缺乏 ground truth 对融合性能的影响,监督知识约束下的互补表达能力比先验知识更有指导意义。此外,作者还设计了一个交叉特征增强模块 CEM(cross-feature enhancement module),该模块利用自己实现的自注意和互注意特征来引导每个分支细化特征,然后促进跨模态互补特征的整合。
Motivation
有监督方法的有效性通常依赖于具有标注信息的大量训练数据,且应与测试数据表现出一致的统计特征。因此,对于 IVIF 任务,由于传感器硬件特性和任务复杂性限制,收集这些数据通常很昂贵,要耗费很大的人力,或在技术上具有挑战性。虽然一些方法利用 fusion definitions 标注小批量的训练数据来实现 IVIF,但训练数据不足使模型无法充分挖掘源图像的内容,导致泛化能力有限。在这种情况下,基于 DL 的 IVIF 方法通常需要结合某种形式的标注或先验知识来促进融合过程,减轻由于缺乏 ground truth 约束而导致的限制。
针对上述问题,本文提出了一种基于半监督迁移学习的 IVIF 模型 STFuse,该模型通过参数学习估计每个源图像的融合贡献,得到融合图像。本文的主要思想是将监督情况下的多焦点图像融合 MFIF 的互补特征提取能力转移到 IVIF,以指导跨模态信息的融合。因为每个子融合任务基本上都是通过捕获源图像之间的互补特征来进行融合的。然而,由于子任务具有不同的任务属性,研究人员在设计具有互补特征的感知方案时考虑了任务属性的差异。
本文的核心是利用梯度信息构建引导损失,有效地从原始模型中过滤掉与 IVIF 任务无关的非增益知识。具体来说,在研究 MFIF 和 IVIF 之间的共性后,作者观察到这两个任务都旨在生成具有清晰纹理和丰富细节的高质量融合图像,图像中具有丰富边缘和纹理特征的梯度信息。这就是说,两种不同方法的融合图像都有效地保留了源图像的梯度信息,这是二者的共性所在。此外,为了提高解码器预测的融合贡献的准确性,本文引入了一个跨特征增强模块 CEM。该模块采用跨通道注意力机制细化来自不同分支的特征信息,从而防止源图像信息的冗余,优化融合过程。
Method
在 IVIF 融合子任务中,融合图像应包含来自不同源图像的互补特征。也就是说,每个源图像都应该以互补的方式对融合图像做出贡献。所以可将融合任务看作是一个估计任务,目标是估计每个源图像的融合贡献。因此,融合图像可以表示为:\(F = w_{A} \otimes I_{A} + w_{B} \otimes I_{B}\)。其中 w 表示源图像 A、B 对融合图像 F 的贡献度,\(\otimes\) 表示对应元素相乘(Hadamard product,哈达玛积)。
只要估计出 \(w_A\) 和 \(w_B\),融合问题就迎刃而解了。怎么估计呢?让我们转向 MFIF 这个融合子任务。首先,MFIF 得是个有监督模型,然后我们才能利用里面的知识。但我们也不能采用“拿来主义”,因为 MFIF 与 IVIF 的属性是不一样(换个高级点儿的词:不匹配)的,直接使用 MFIF 的有监督模型肯定对 IVIF 起不到任何好的作用。经过分析,MFIF 和 IVIF 都试图尽可能多的感知和利用源图像的互补信息,以生成满足各自任务需求的高质量图像。高质量融合图像是有共同点的:纹理细节信息十分丰富(要不然也谈不上质量高)。说到细节信息,你第一时间能想到什么?—— Yes,梯度!梯度信息可以作为从 MFIF 到 IVIF 的跨任务转移知识进行利用的一种指导。
接下来出场的就是本文的核心:Semisupervised transfer learning-based fusion model,即基于转移知识学习的半监督融合模型。这个模型有点像教师—学生模型(知识蒸馏与迁移学习在模型优化中的应用)。知识蒸馏采取 Teacher-Student 模式:将复杂且较大的模型作为 Teacher,结构较为简单的模型作为 Student,用 Teacher 模型来辅助 Student 模型的训练,Teacher 模型学习能力强,可以将它学到的知识迁移给学习能力相对弱的 Student 模型,以此来增强 Student 模型的泛化能力。复杂笨重但是效果好的 Teacher 模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的 Student 模型。
但本文中不是套用知识蒸馏的框架(真的只是有点像而已),因为 MFIF 和 IVIF 各自学习能力很难说孰强孰弱(都不弱~)。STFuse 包含一个学生模型和一个教师模型,其中教师模型通过基于学生模型的 EMA(exponential mean average,指数平均)方式更新。学生模型最初使用标记数据进行预训练。随后,未标记数据和标记数据形成混合数据,传入学生模型中进行训练,这是为了避免训练过程中的知识遗忘。在每次训练迭代中,教师模型使用未标记数据来用于生成伪标签,以便伪标签监督未标记的数据,标签监督标记数据。同时,引导损失 \(L_g\) 确保保留跨模态的通用性知识(专注于挖掘互补的梯度信息),同时过滤任务专有的知识,尽量避免任务属性的影响(也就是学好的方面别学坏的)。最终让学生模型(作为目标模型:target model)用于 IVIF 任务。
STFuse contains a student model and a teacher model, where the teacher model is updated by EMA manner based on the student model. The student model is initially pretrained with labeled data. Subsequently, unlabeled and labeled data form the mixed data. And in each training iteration, the teacher model is used to generate pseudo-labels so that the pseudo-labels supervise the unlabeled data and the labels supervise the labeled data. Meanwhile, guidance loss ensures that generality knowledge of cross-modal is retained while individual knowledge is filtered.
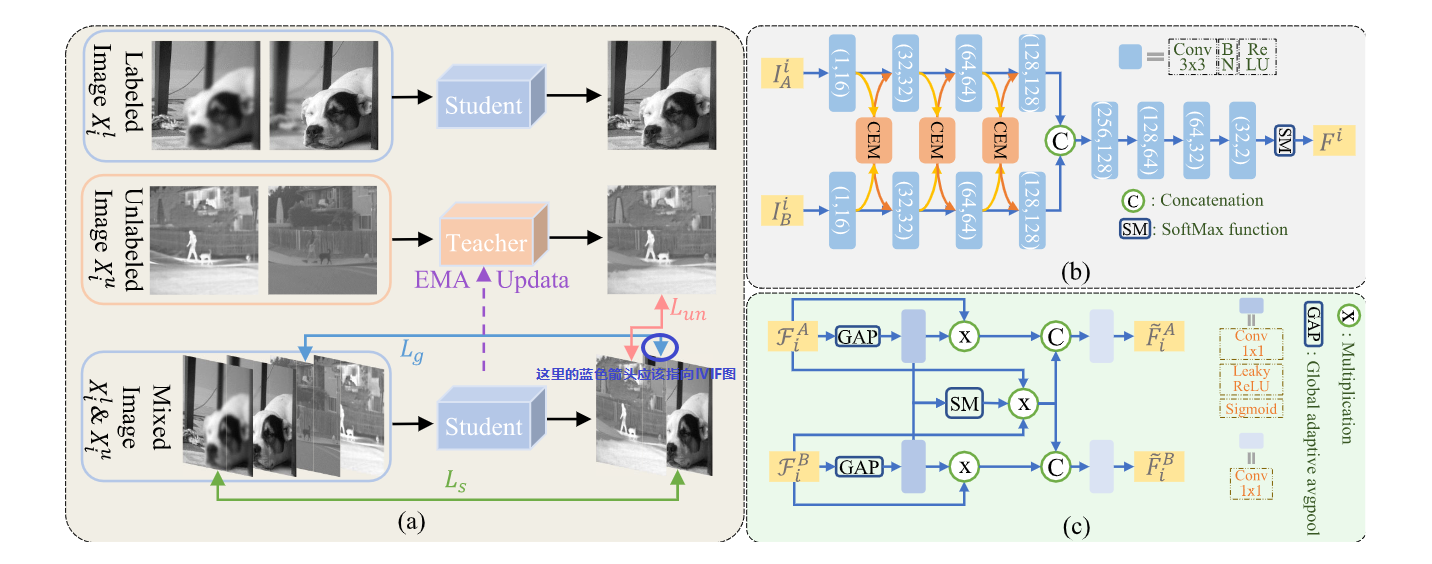
上图是 STFuse 的总体框架和流程。图(a)是训练的策略。图(b)是网络的架构,包含一个双分支、权重共享的编码器 Encoder 和一个解码器 Decoder,Encoder 负责提取信息,Decoder 负责重建图像(生成融合图像)。很明显,Encoder 的性能直接影响最终的融合结果。为了进一步提高 Encoder 的信息提取能力,作者加了如图(c)所示的 CEM 模块,其利用自注意力和互注意力(不是 Attention 机制,是自己实现的网络结构)来精炼不同分支的特征,提高模型对互补特征的敏感性。
图中:\(I_A^i\) 和 \(I_B^i\) 代表源图像,i 代表第 i 个图像,经过卷积模块(卷积、BN、ReLU)得到聚合的特征 \(F^A_{i}\) 和 \(F^B_{i}\)。然后传入 CEM 模块,一条分路经过 GAP(global adaptive pooling)操作计算各自的全局信息,再经过卷积(卷积、LeakyReLU、Sigmoid)、Multiplication(对应元素相乘,即哈达玛积)得到 self-refining feature(抑制了不必要的场景理解信息);另一条分支是经过 GAP、卷积、Softmax(SM)、Multiplication 得到 mutual-refining feature(信息交互,加强互补特征提取)。最后经 Concatenation(向量特征拼接)操作 + 卷积得到最终的 refinement feature:\(\widetilde{F}_i^A\) 和 \(\widetilde{F}_i^B\)。
Loss
labeled dataset: \(D_l = \{(X_i^l, \
Y_i^l)\}^N_{i=1}~~\) 取自:多聚焦数据集
unlabeled dataset:
\(D_u = \{(X_i^u)\}^N_{i=1}~~\)
取自:红外可见光数据集
mixed dataset: \(D_t = \{D_l \cup D_u\}\)
(正式训练阶段学生模型使用的训练集)
X 包含两类源图像 A、B:\(X_i = \{I_A^i, \ I_B^i\}^N_{i=1}\)
在使用 \(D_l\) 的预训练阶段,Student 模型可以学习 generic knowledge \(\phi _g\)(i.e., 通用互补特征提取能力)和 attribute task knowledge \(\phi _a\)(i.e., 聚焦区域检测能力)。之后在自训练框架(图a)中,Student 模型将着重提取 \(\phi _g\)。
学生模型是要训练的目标模型,它使用指数平均 (EMA) 将每一轮更新的学生模型参数 \(\theta _s\) 分配给教师模型参数 \(\theta _t\),而教师模型的预测结果(伪标签)将被视为学生模型学习的额外监督。
学生模型的优化目标:最小化总损失 \(L_{total}\):
\[L_{total} = L_{un} + L_s + \lambda L_g\]
上式中,\(L_{un}\) 代表 unsupervised loss,\(L_s\) 代表 supervised loss,\(L_g\) 代表 guidance loss。
\[ L_{un} = \Vert \theta _s(X_i^u) - \theta _t(X_i^u) \Vert_1\]
\[ L_s = \Vert \theta _s(X_i^l) - Y_i^l \Vert_1\]
\(L_s\) 用于确保 \(D_l\) 中 \(X_i^l\) 的融合结果与其对应的标签 \(Y_i^l\) 尽量相似,\(L_{un}\) 用来确保 \(D_u\) 中 \(X_i^u\) 的融合结果与其对应的伪标签尽量一致。在功能上,二者都旨在最小化输出和输入之间的差异,从而促进模型从 MFIF 中获取监督知识。
然而 \(\phi _a\) 的存在会影响模型在 IVIF 的性能,因此作者使用梯度信息作为“过滤器”来促进监督知识的跨任务利用。作为指导项,我们不需要它准确地计算图像的梯度信息,只要从广义的角度指导模型学习就够了。因此作者选择 Sobel 算子作为梯度信息的统计工具。引导损失 \(L_g\) 可以表示为:
\[\begin{align} L_g &= \Vert \nabla \theta _s(X_i^u) - \nabla X_i^u \Vert_1 \\ &= \Vert \nabla \theta _s(X_i^u) - \nabla (I_A)_i^u \Vert_1 + \Vert \nabla \theta _s(X_i^u) - \nabla (I_B)_i^u \Vert_1 \nonumber \end{align}\]
其中 \(\nabla\) 表示 Sobel operator。
Summary
本文的一大亮点是将多聚焦融合任务和红外可见光融合任务进行了关联,通过分析二者的异同,利用 MFIF 和 IVIF 之间的共性(梯度约束),借助 MFIF 的优势,完成缺乏 ground truth 的 IVIF 任务。
本文模型整体比较简单,思路清晰,但是未公开源代码,因此对实验结果的真实性验证和复现需要费一番功夫。不过本文的思想还是很新颖的,值得学习。
不过阅读完本文后还有一个问题:本文提出的 Student 和 Teacher 模型的网络结构分别是什么?个人认为二者都是上图(b)中的结构。因为学生模型作为处理 IVIF 任务的目标模型,需要从 MFIF 任务中进行学习,而教师模型则需要根据红外-可见光训练数据生成伪标签,进而用于损失函数之中。再加上教师模型的参数由学生模型的参数通过 EMA 方式更新,因此我觉得二者网络应该一样,以保证上述功能的实现。